-
DBMS - Hash Table대학/데이터베이스 2023. 6. 3. 21:26
hash table은 해시 함수를 이용해서 어떠한 입력이라도 특정 정수로 치환된 주소에 데이터를 저장할 수 있는 자료구조로
일반적으로 O(1)의 시간복잡도를 갖는다.
사실 해시함수를 구현하기에 따라 해시 테이블의 탐색 시간 복잡도가 크게 차이날 수 있는데,
이 포스트는 자료구조의 해시 테이블를 다루는 것 보다,
데이터베이스에서 데이터를 다룰 때 해시 테이블을 사용하는 방식을 다루기 때문에 깊은 내용은 생략합니다.
해시 테이블을 설계함에 있어 몇가지 부분에서 Trade-off가 요구됩니다.
- Hash function
해시 함수는 큰 범위의 입력 값을 작은 도메인으로 줄여야 합니다.
그 과정에서 필연적으로 다른 입력에 대해 같은 값(collision)이 나올 수도 있습니다.
이 과정에서 collision rate를 내리기 위해 복잡한 해시 함수를 구현하면 해시 함수가 동작하는 시간이 길어질 수 밖에 없습니다.
- Hashing scheme
해싱 이후에 collision이 일어나는 경우에 처리하는 방법은 크게 두 가지가 있을 수 있습니다.
더 큰 hash table을 할당하여 collision을 없애는 방법,
또는 어떻게든 key를 넣기위한 별도의 명령을 처리하는 방법
위 두 가지 방법은 시간과 공간 복잡도에 영향을 주게 됩니다.
따라서 DBMS 개발시 특징에 맞는 해시 함수를 사용해야 할 것입니다.
이번 포스트에선 여러 Hashing scheme 방법을 소개하고 장단점을 알아봅니다.
참고로 실제 DBMS에서 해시 테이블을 이용해서 데이터를 관리하지는 않습니다.
범위 탐색에서는 해시 테이블을 전혀 사용할 수 없기 때문입니다.먼저 테이블의 크기가 정해진 경우에 사용할 수 있는 Hashing scheme 방법입니다.
- Linear Probe Hashing
- Robin Hood Hashing
- Cuckoo Hashing
Linear Probe Hashing
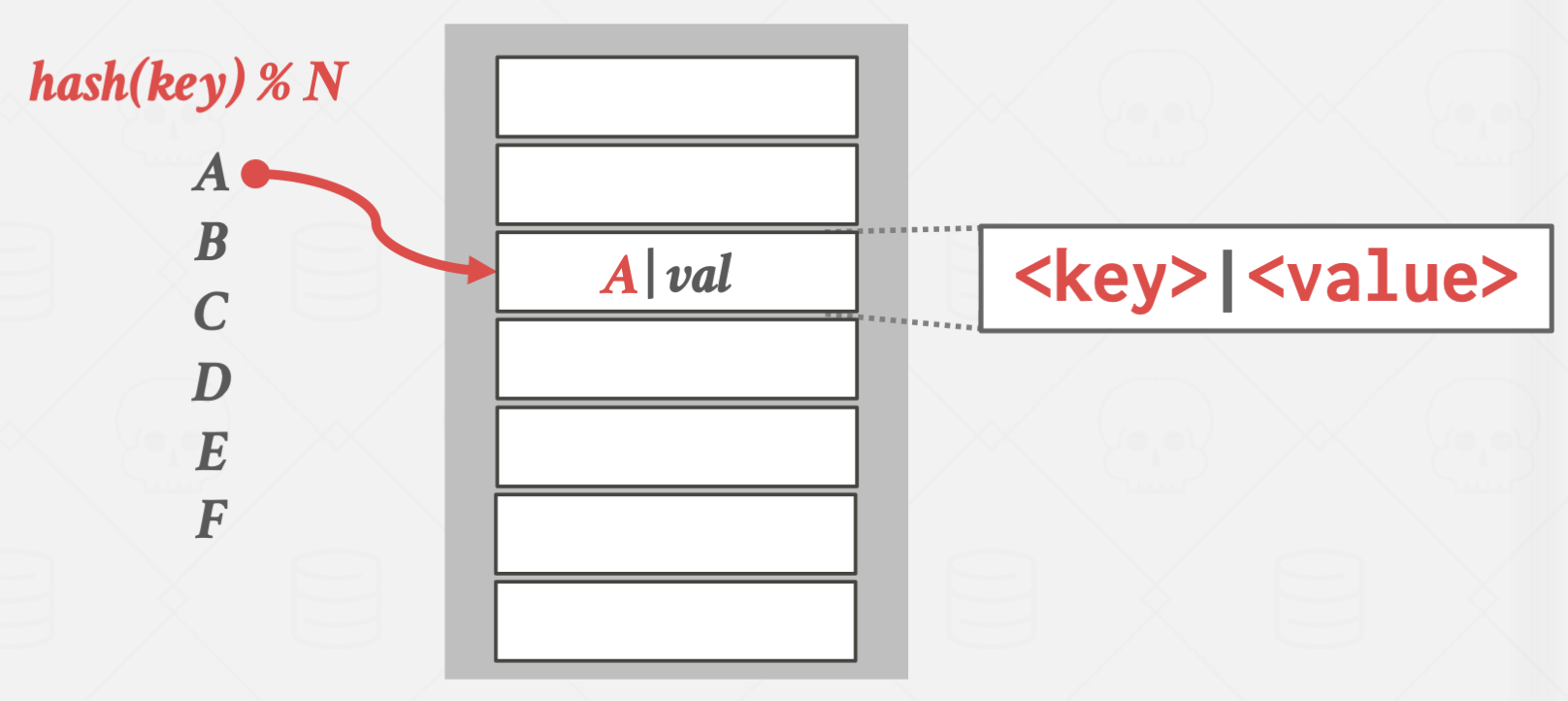
일반적으로 가장 많이 쓰이는 방법이고, 구현도 상대적으로 간단합니다.
collision이 일어나면 바로 다음 슬롯에 데이터를 넣고,
탐색을 멈추기 위해 인덱스에 key과 value값을 동시에 저장합니다.
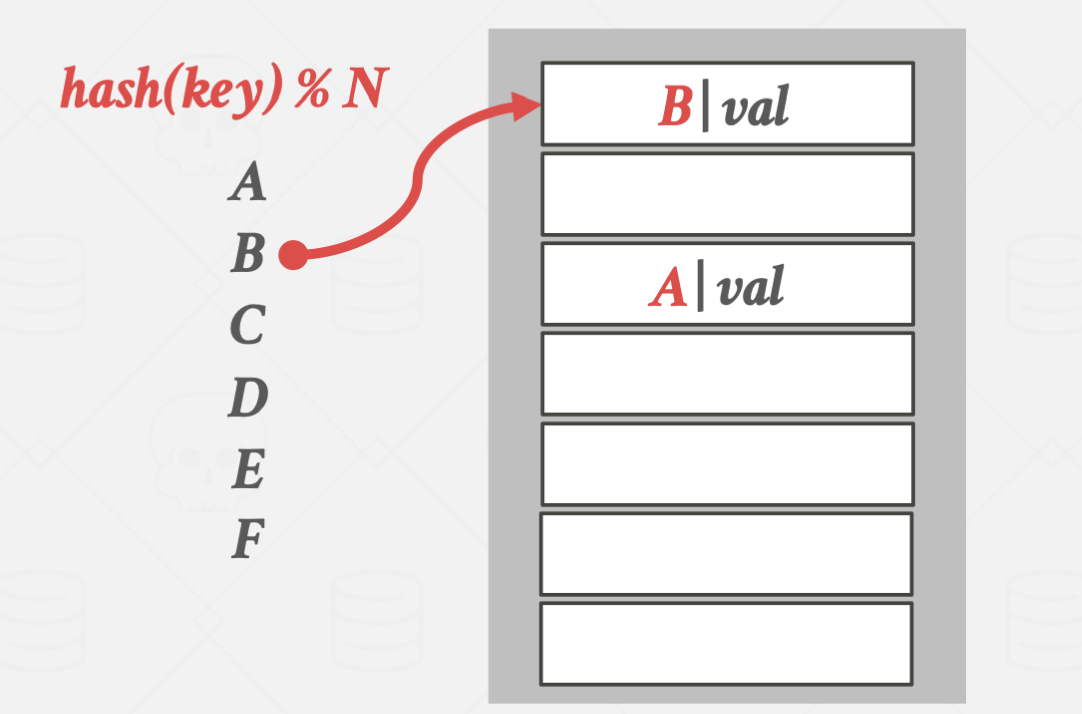
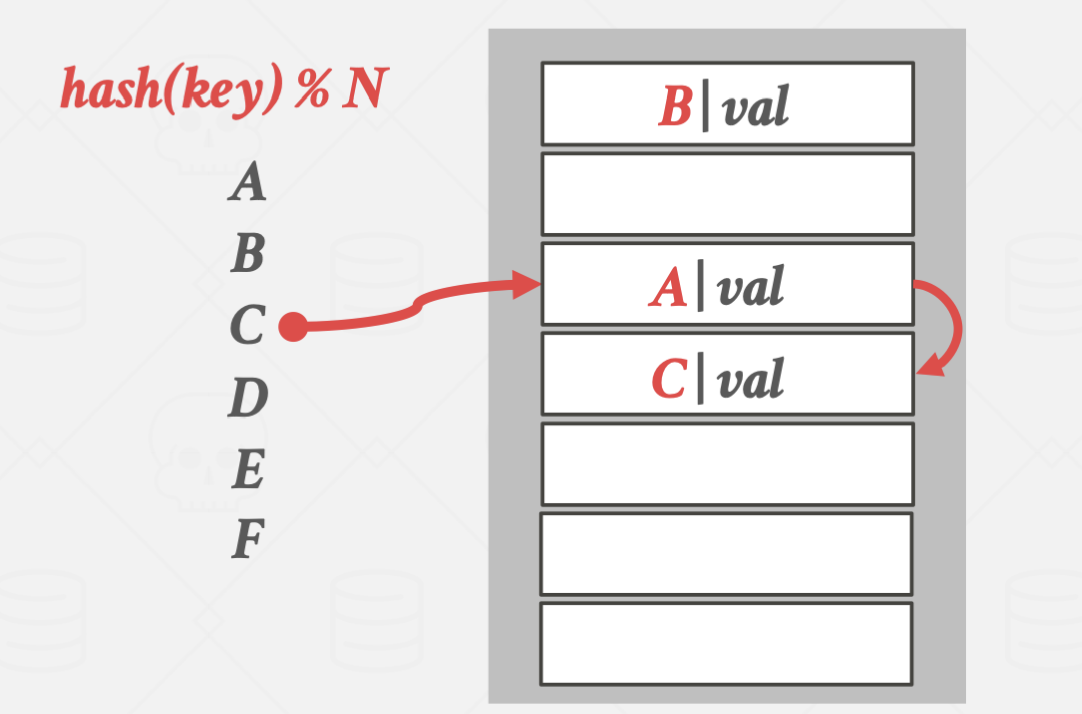
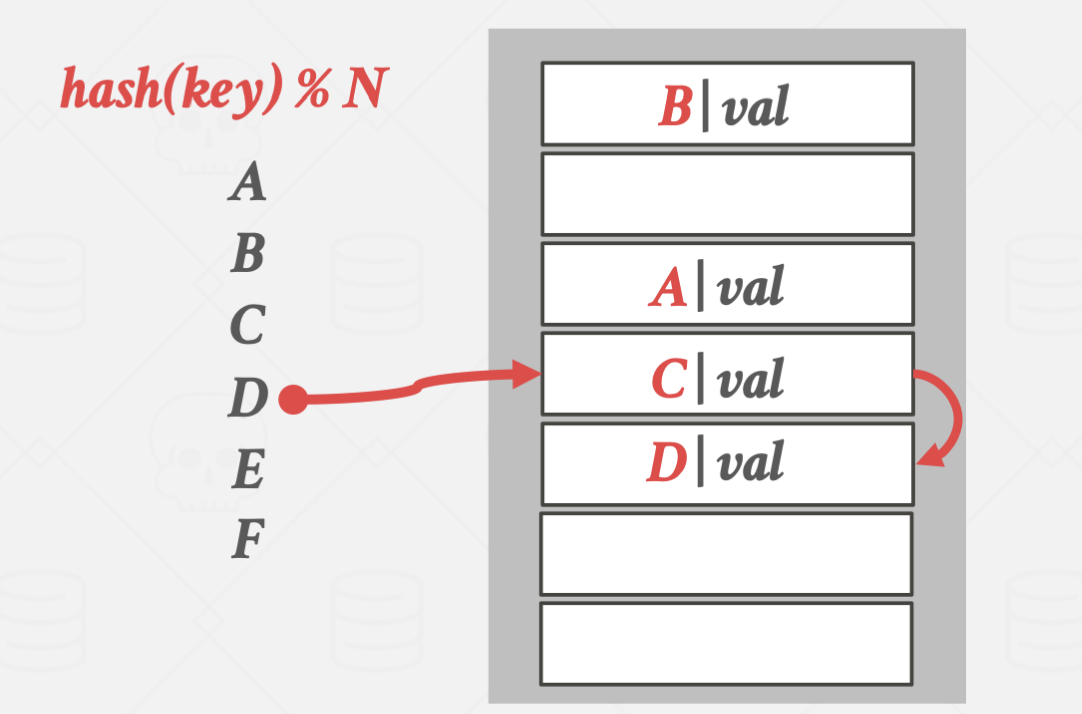
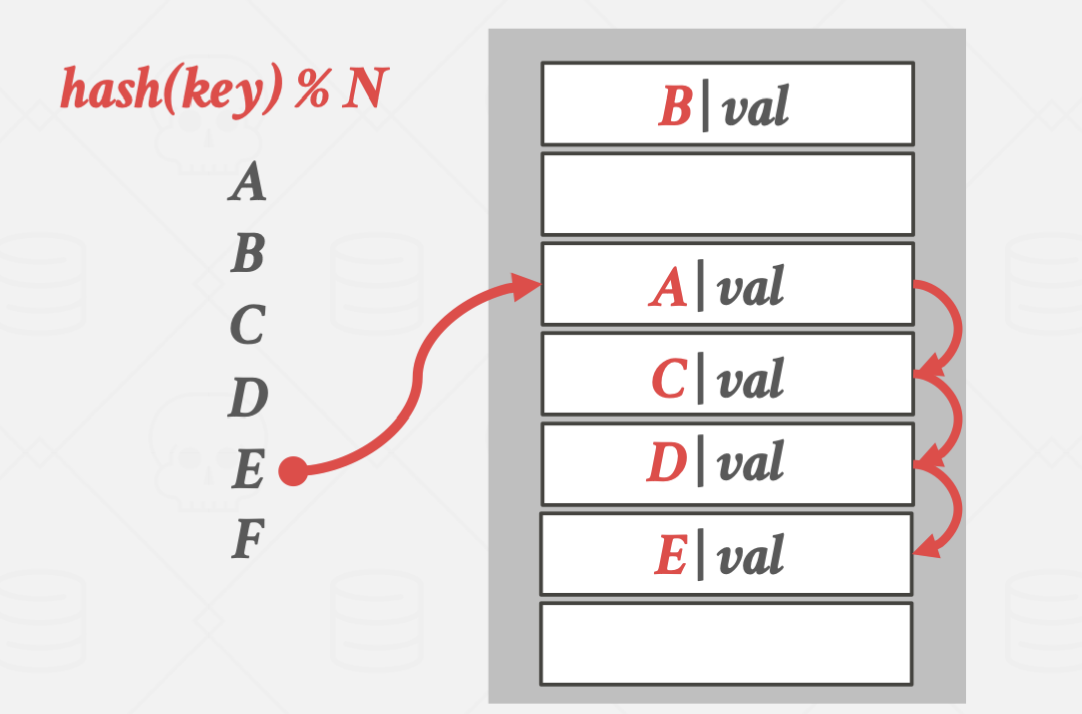
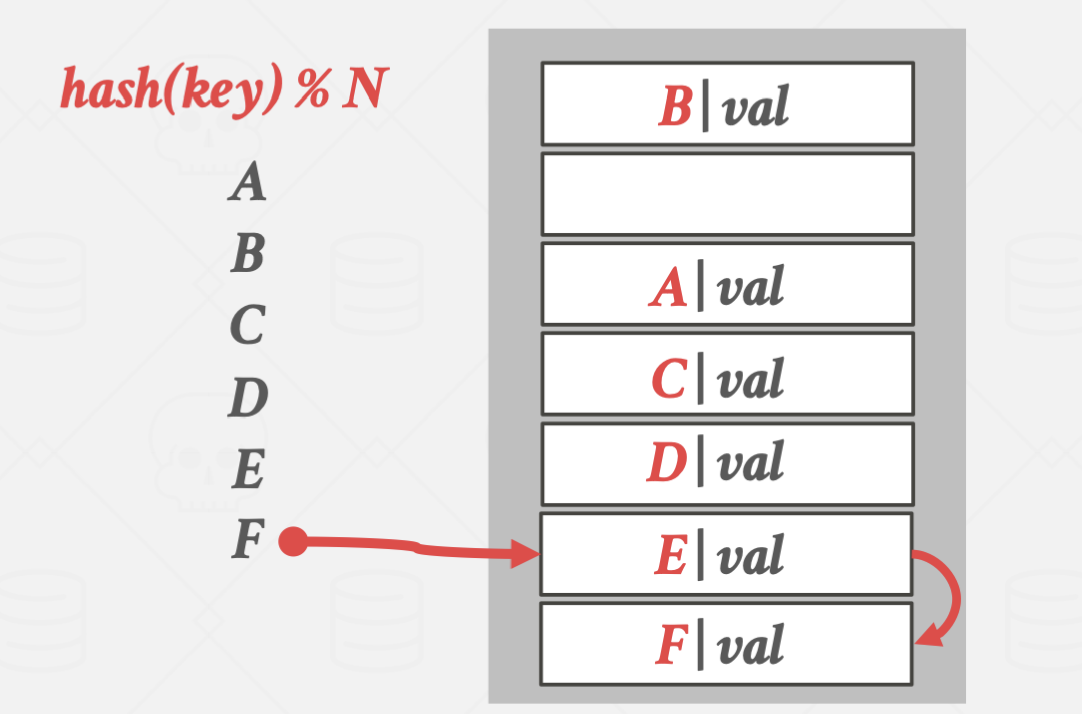
입력과 탐색은 위와 같은 방식으로 진행됩니다.
삭제하는 방식도 위외 같은 방식으로 진행되다가 발견되면 해당 슬롯을 삭제하는데
여기서 문제가 발생합니다.
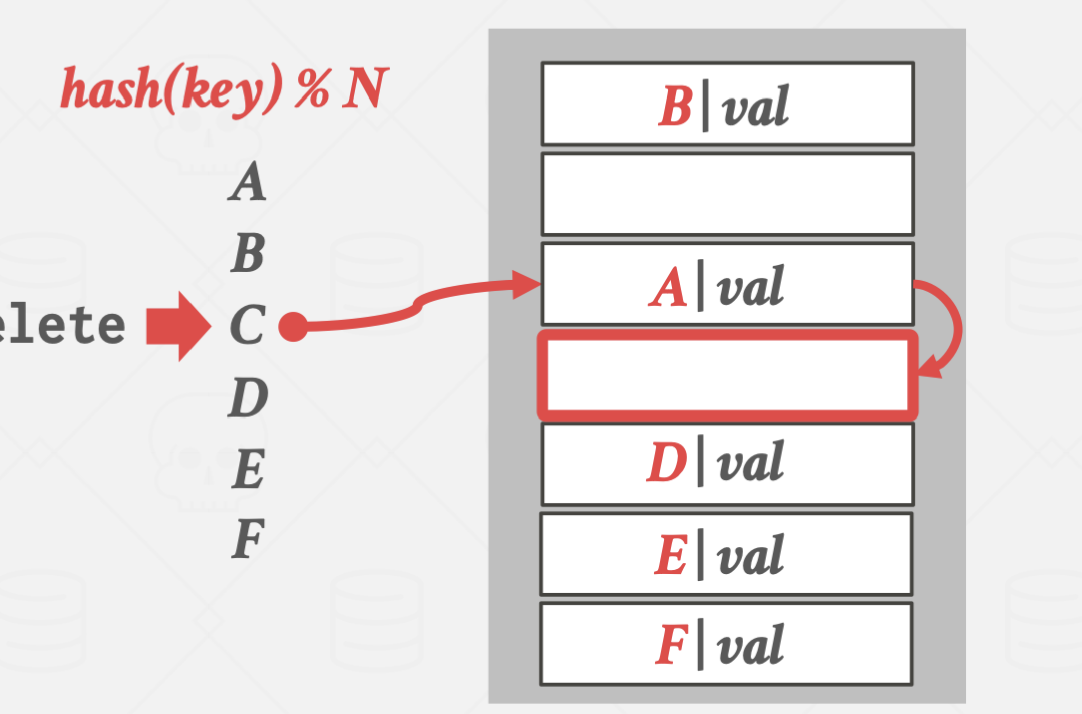
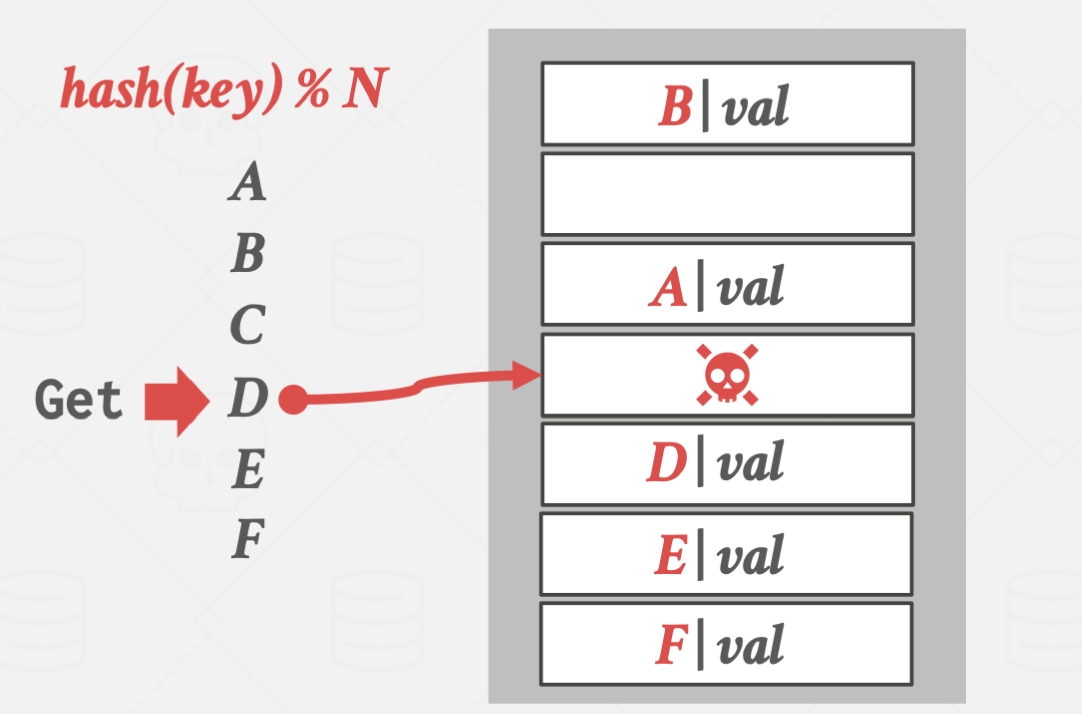
특정 슬롯을 삭제하면 collision이 일어난 key를 탐색함에 있어 문제가 발생합니다.
위 경우에 D를 탐색하지만, hash(D)의 위치가 빈 공간이라 D가 저장되어있지 않다고 판단하는 겁니다.
그렇다고 빈 공간을 매꾸기위해 아래의 모든 슬롯을 위로 당기자니
오버헤드가 너무 크기에 사실상 불가능합니다.
이 경우 별도의 flag를 둬서 데이터는 없지만, 탐색은 더 해야한다는 의미를 주어 해결할 수 있습니다.
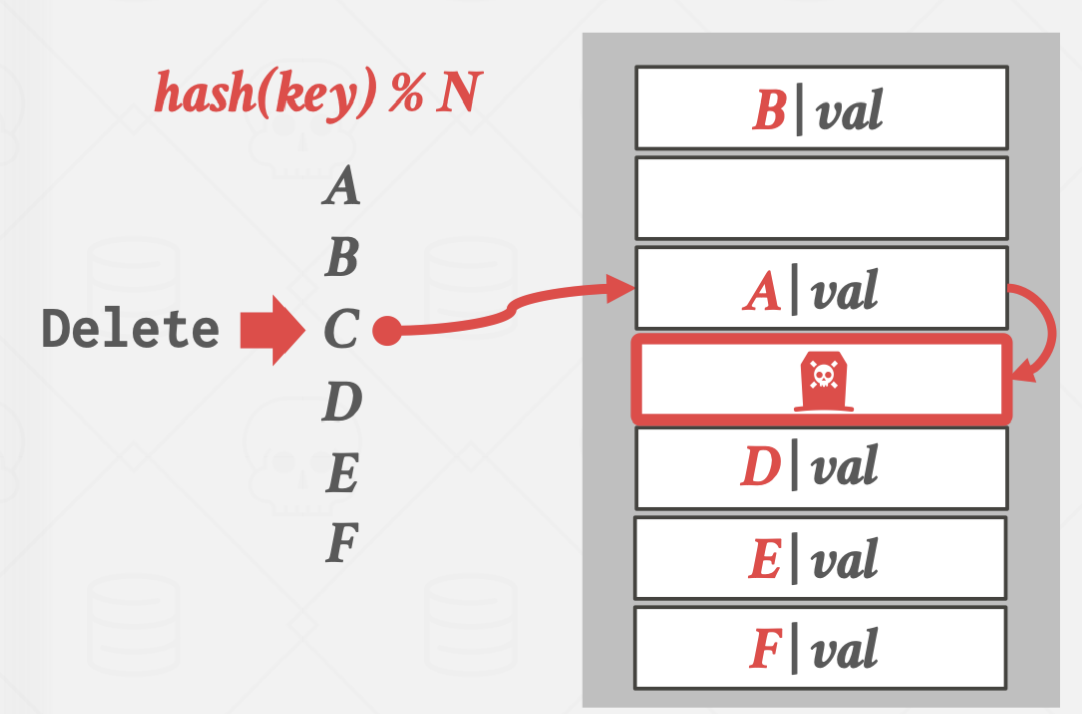
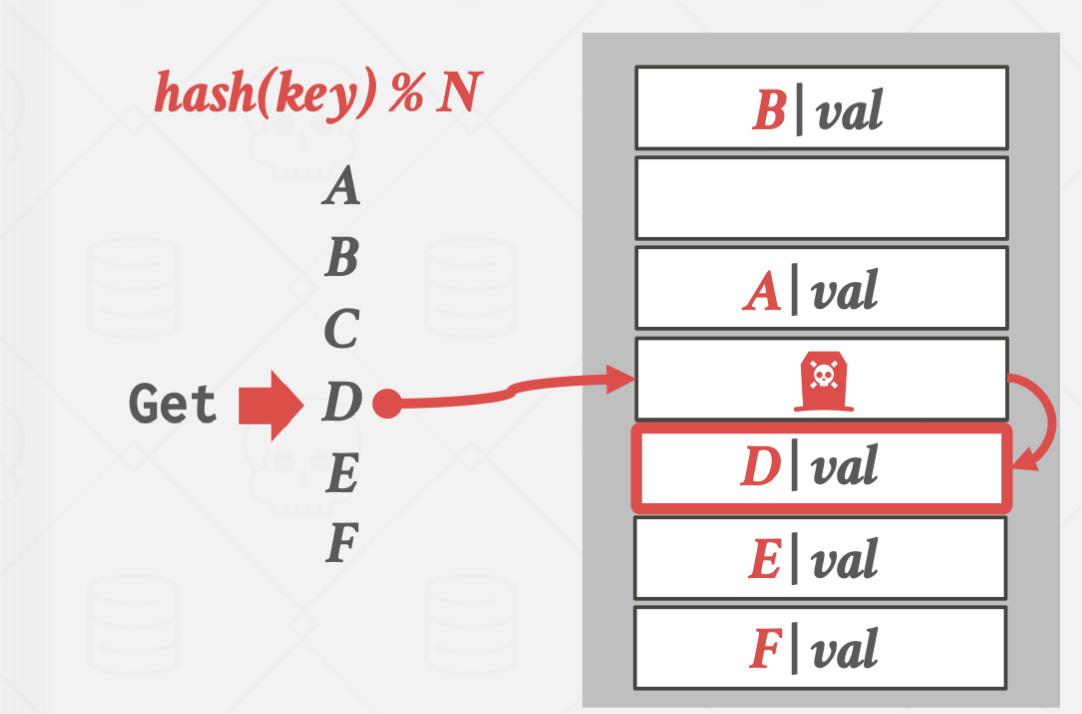

하지만, 이 방법은 해시 테이블의 사용이 많아질 수록 flag의 수도 증가하여
결국 전체 탐색을 하게되는 빈도가 늘어나 좋은 방법이 될 수는 없습니다.
Robin Hood Hashing
로빈후드의 이야기에서 따온 이름입니다.
간단하게 설명하면 탐색이 얼마 걸리지 않은(부자)의 key가 들어갈 자리를 빼앗아
탐색이 오래 걸리는(가난) key가 대신 들어가는 방식입니다.
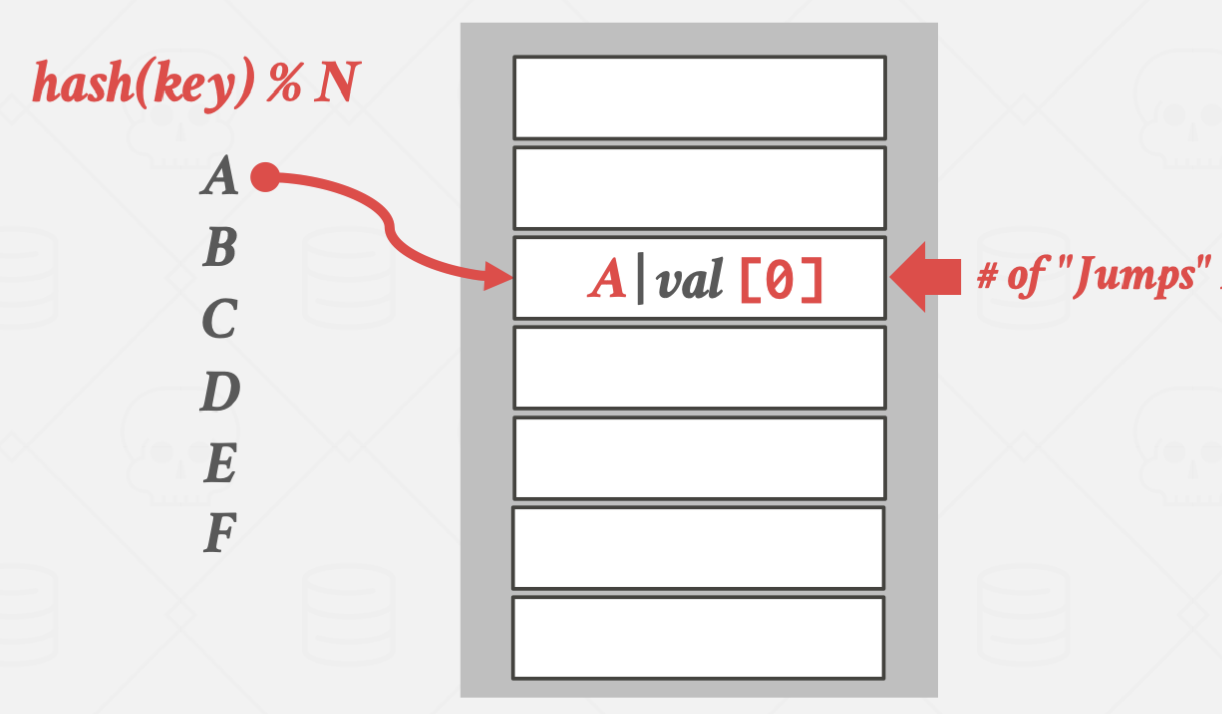
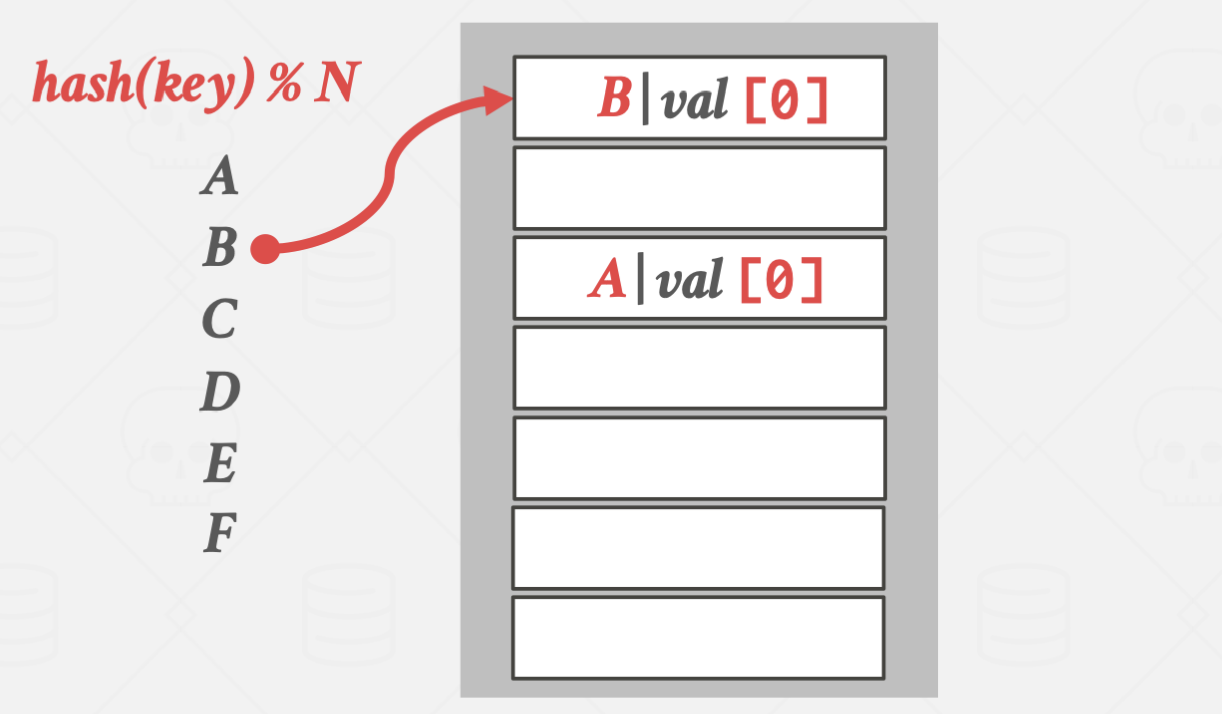
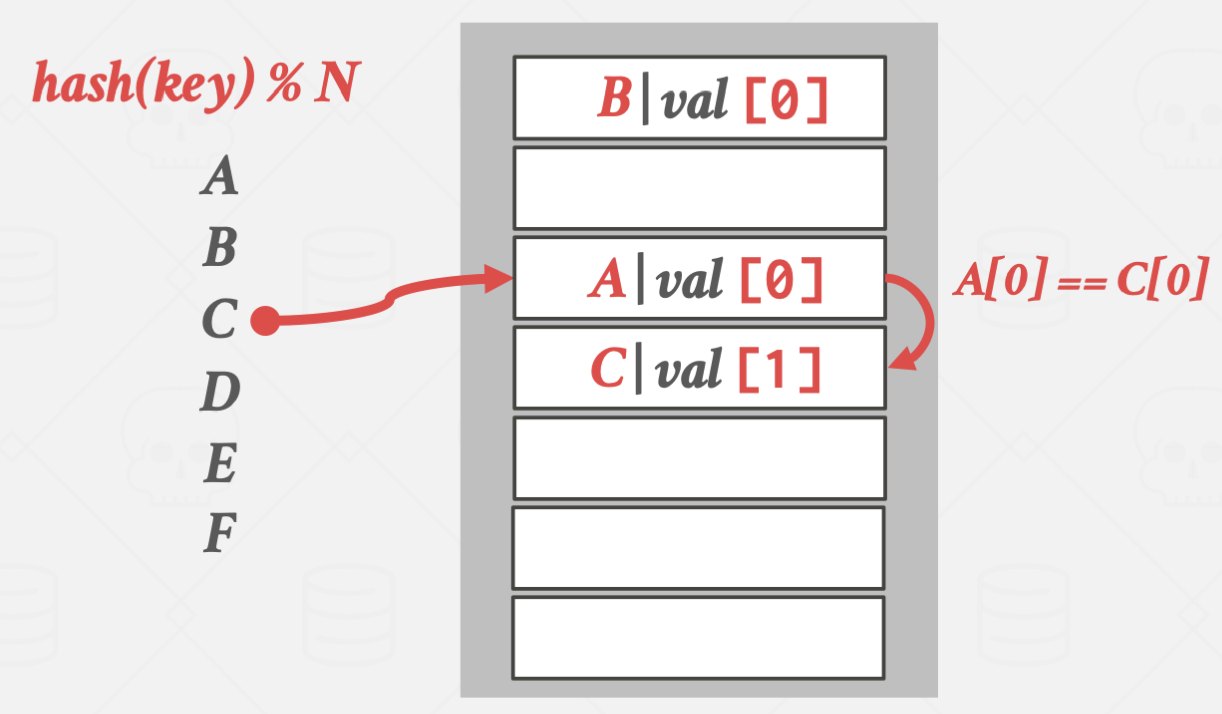
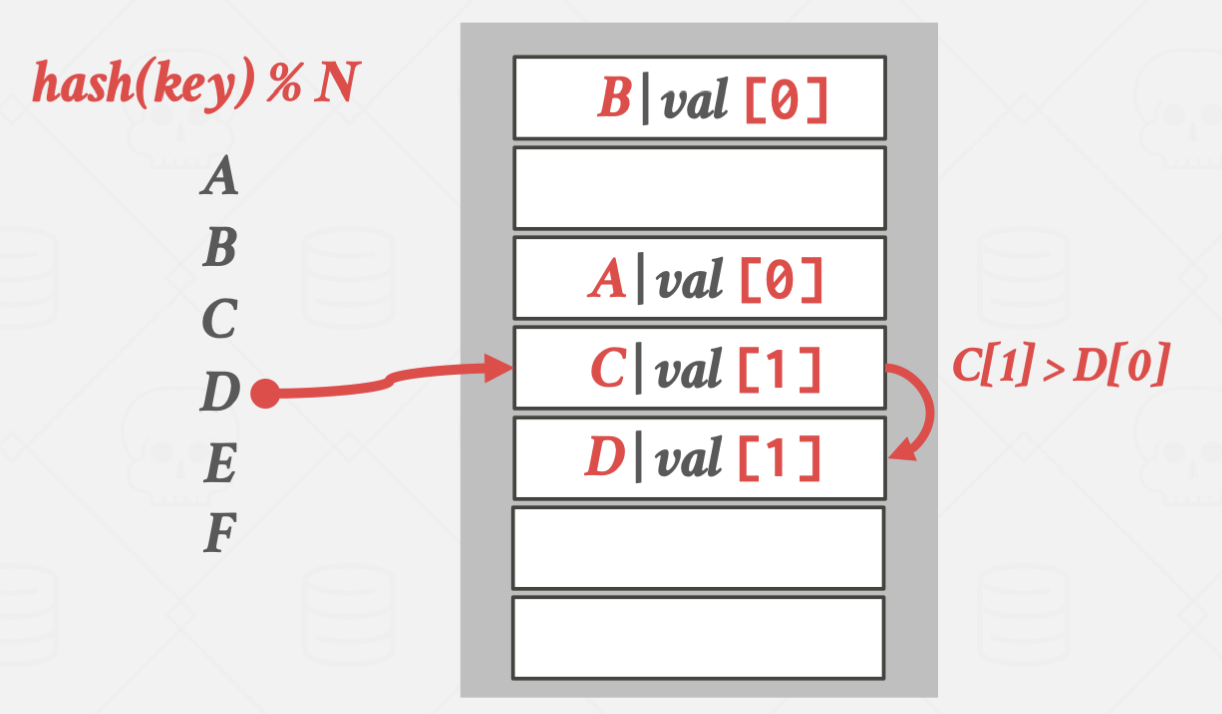

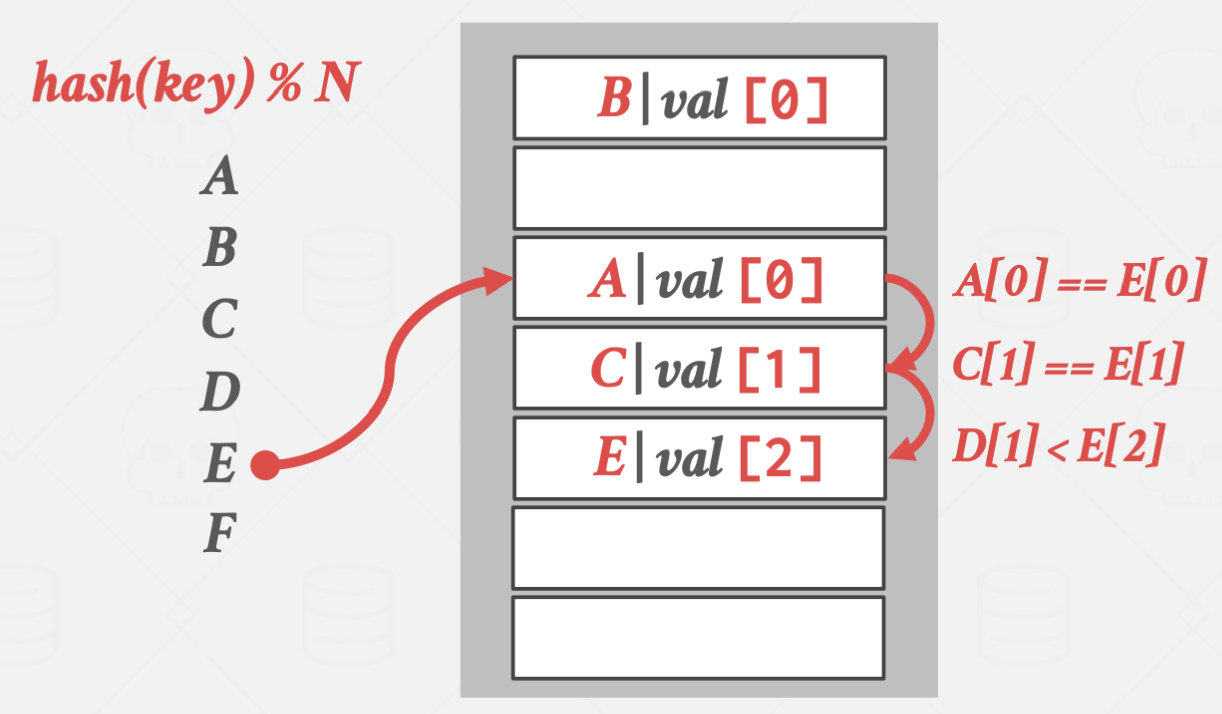
E가 더 탐색시간이 길어지기 때문에 D의 위치를 빼앗았습니다.
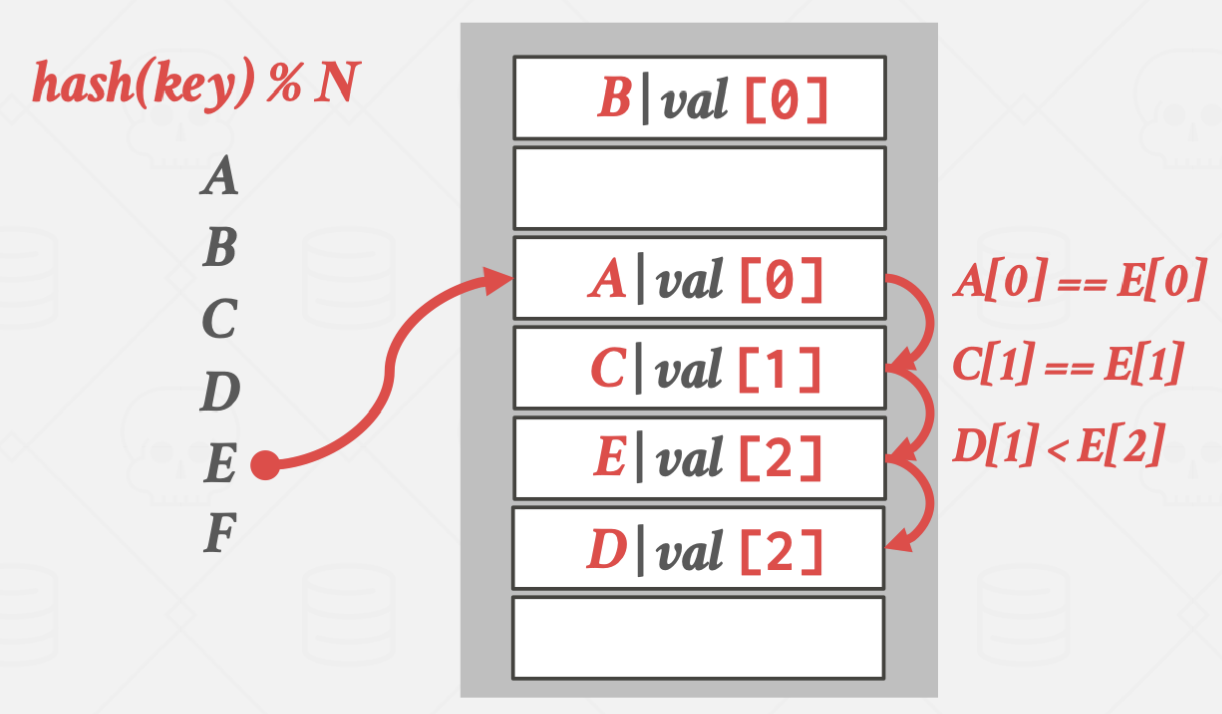
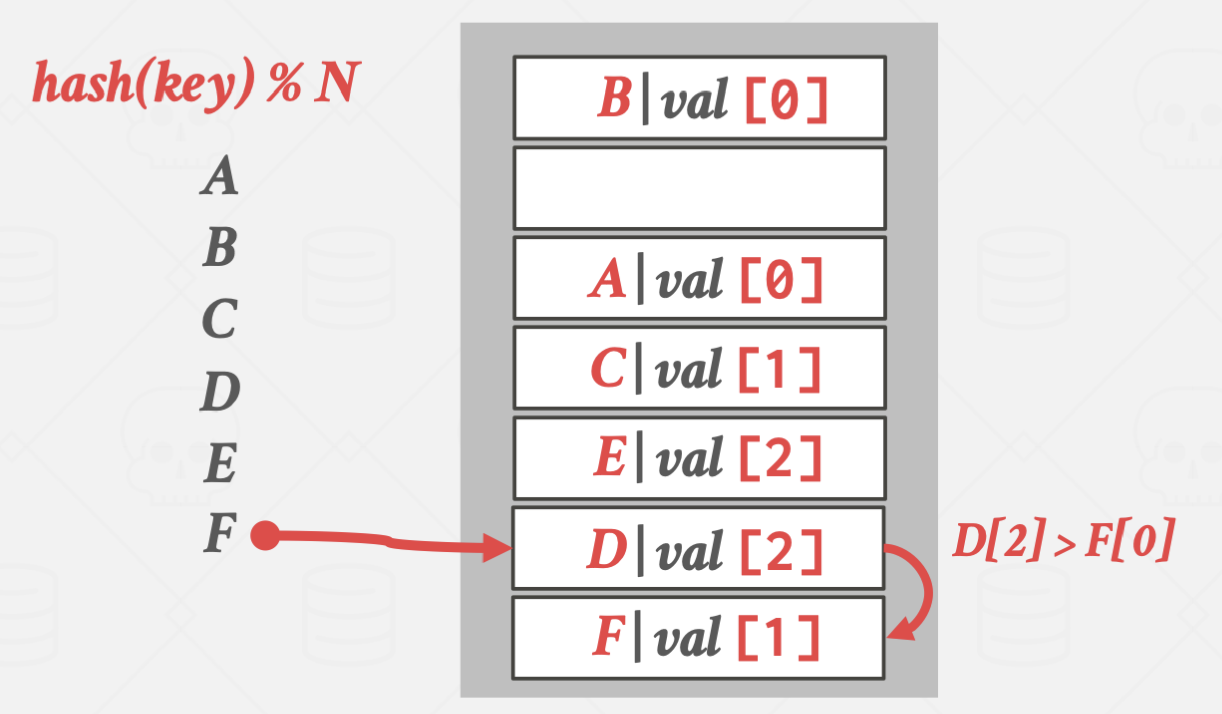
탐색 방식은 Linear Probe방식과 거의 유사합니다.
그렇기에 Average case의 경우 탐색 시간도 비슷합니다.
하지만 Worst case의 경우 Robin Hood의 방식이 더 좋습니다.
Cuckoo Hashing
둥지를 빼앗아 알을 낳는 Cuckoo 새에 비유한 방법입니다.
서로 다른 해시 함수를 사용하는 여러 해시 테이블을 만들어 관리하는 방법입니다.
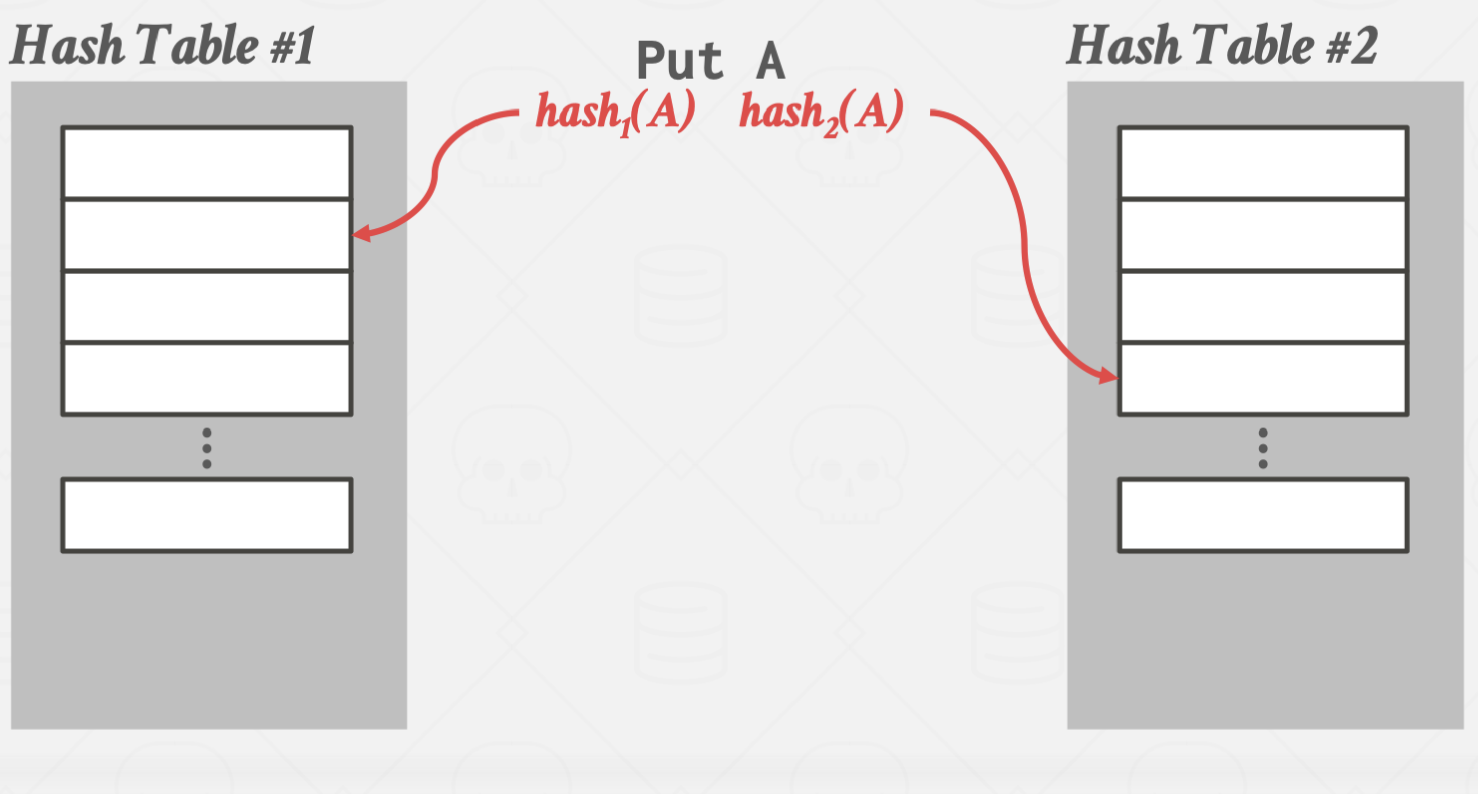
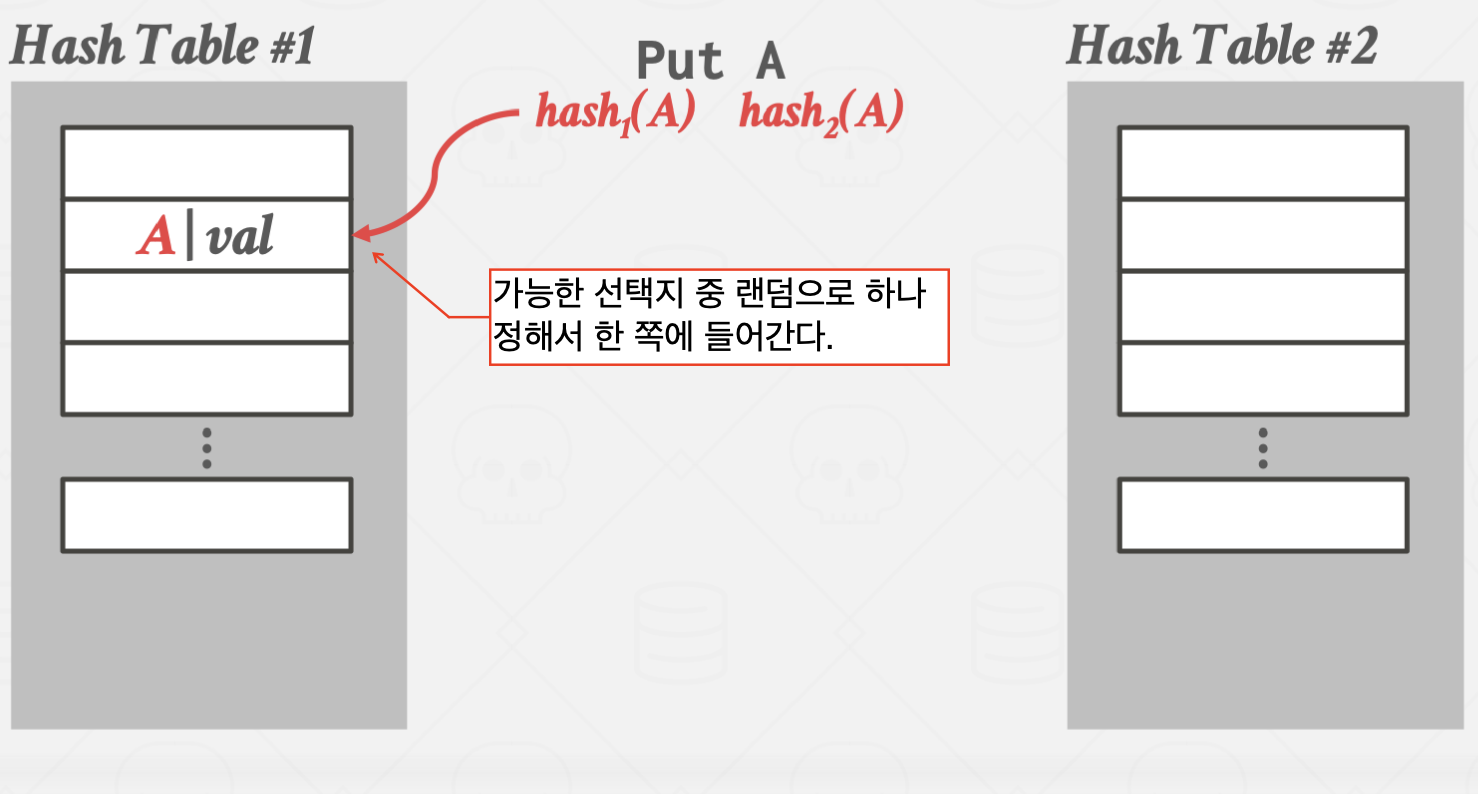
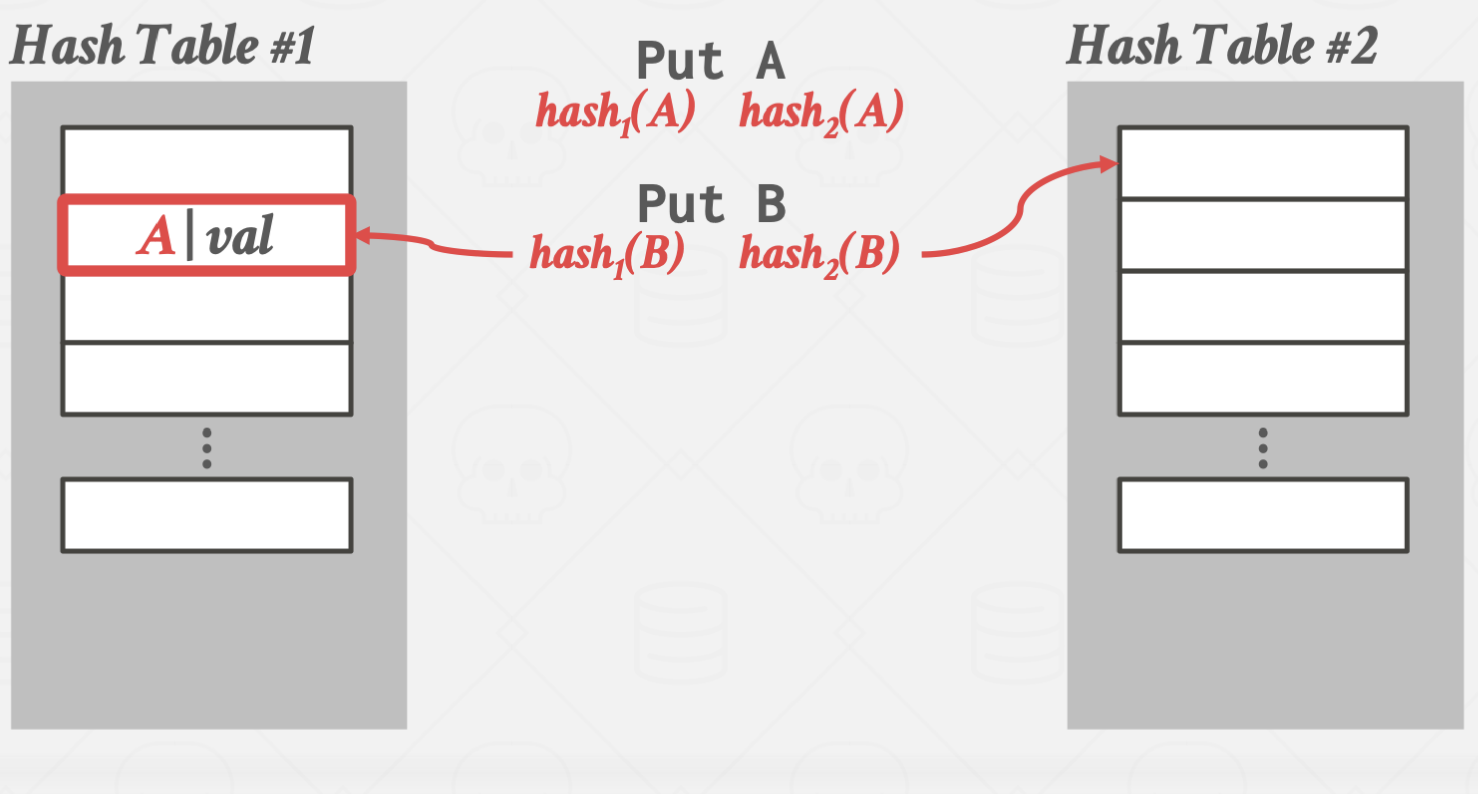
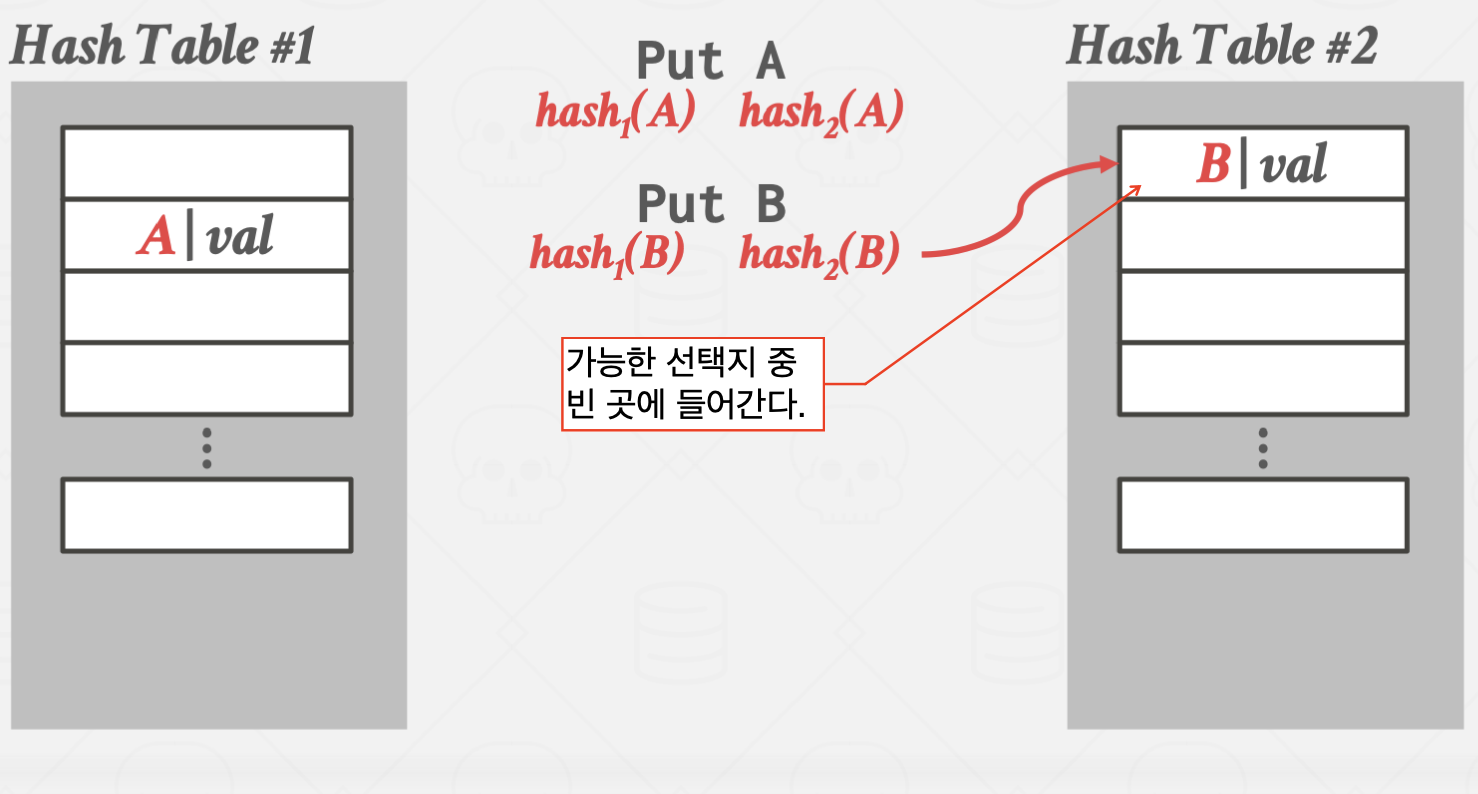
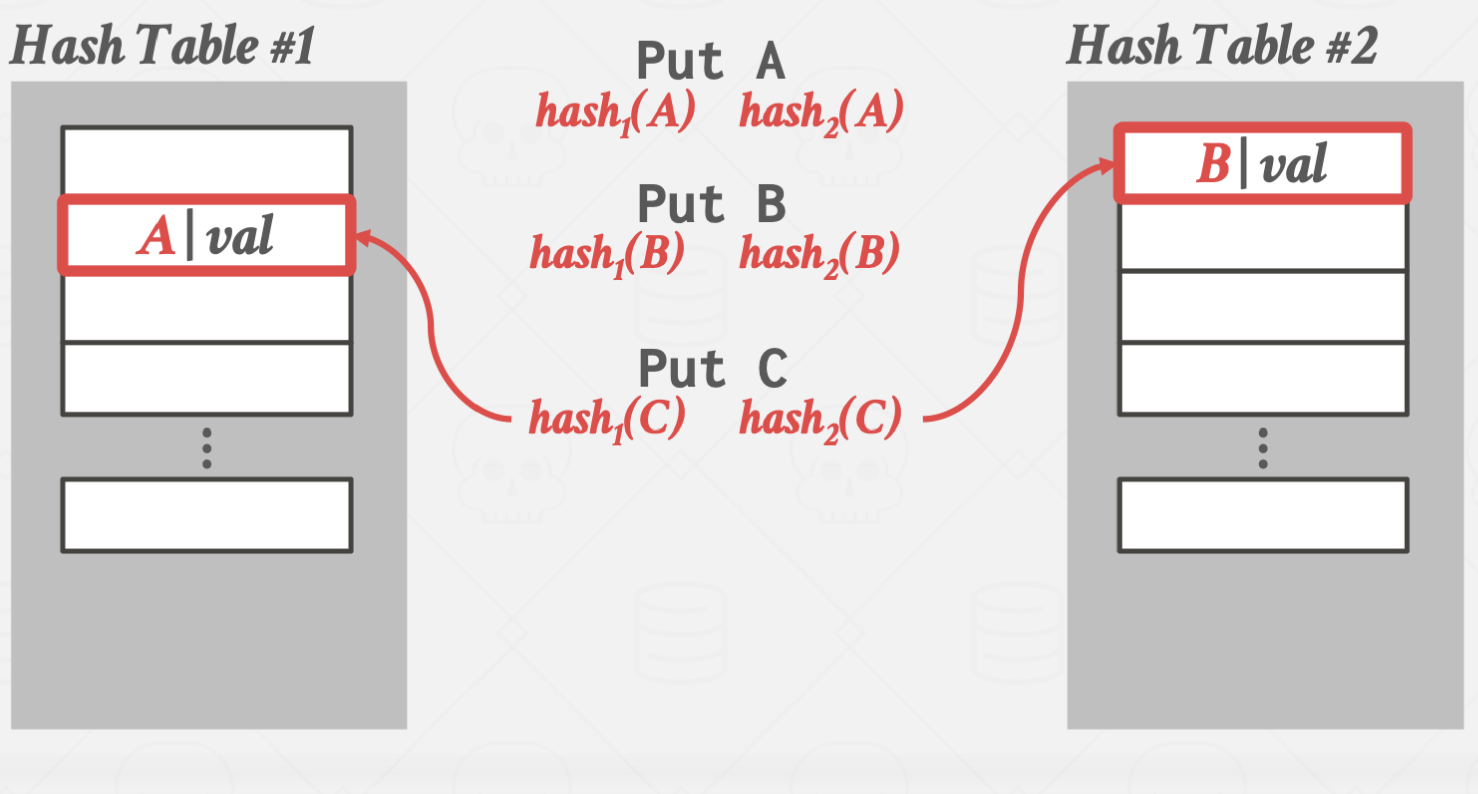

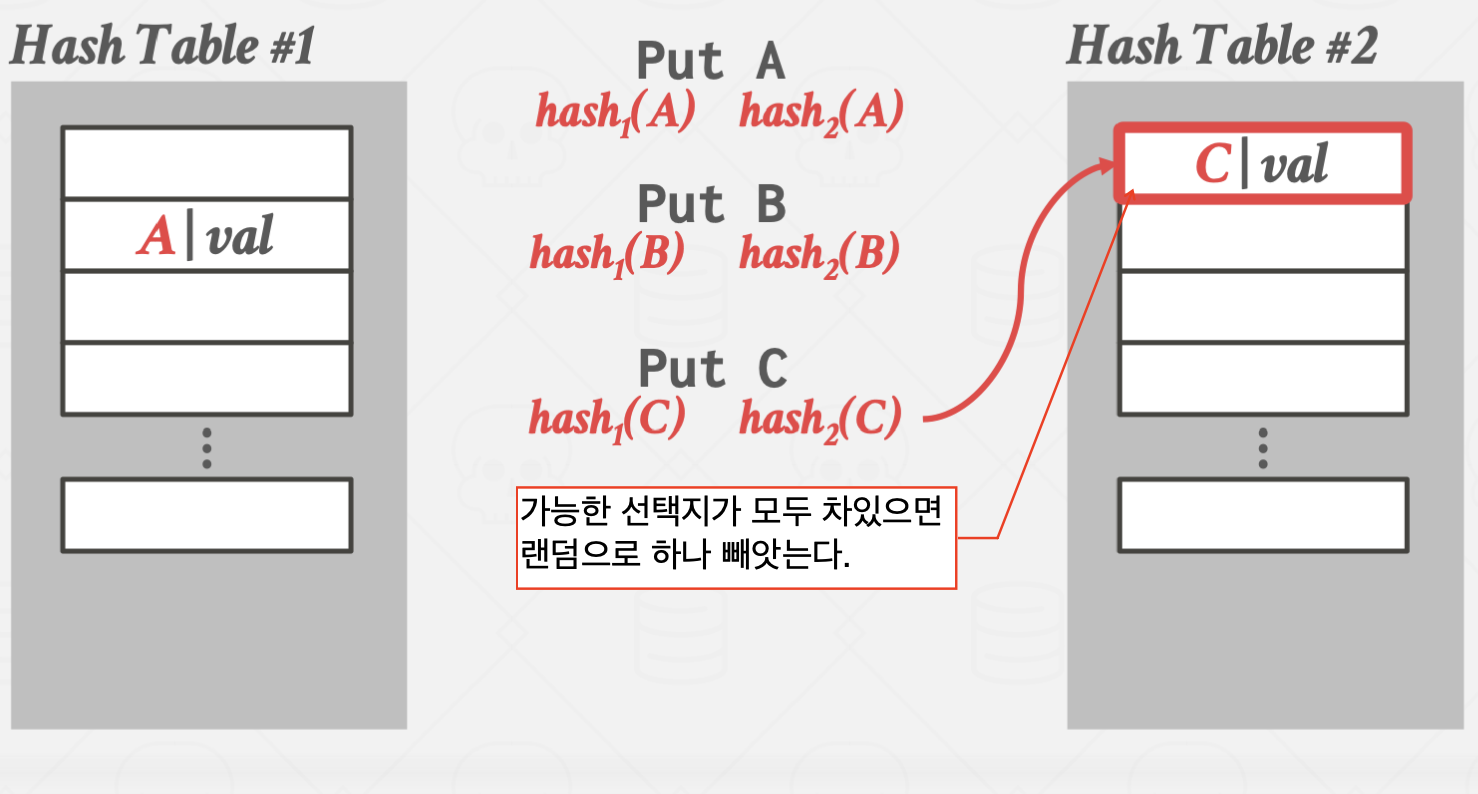
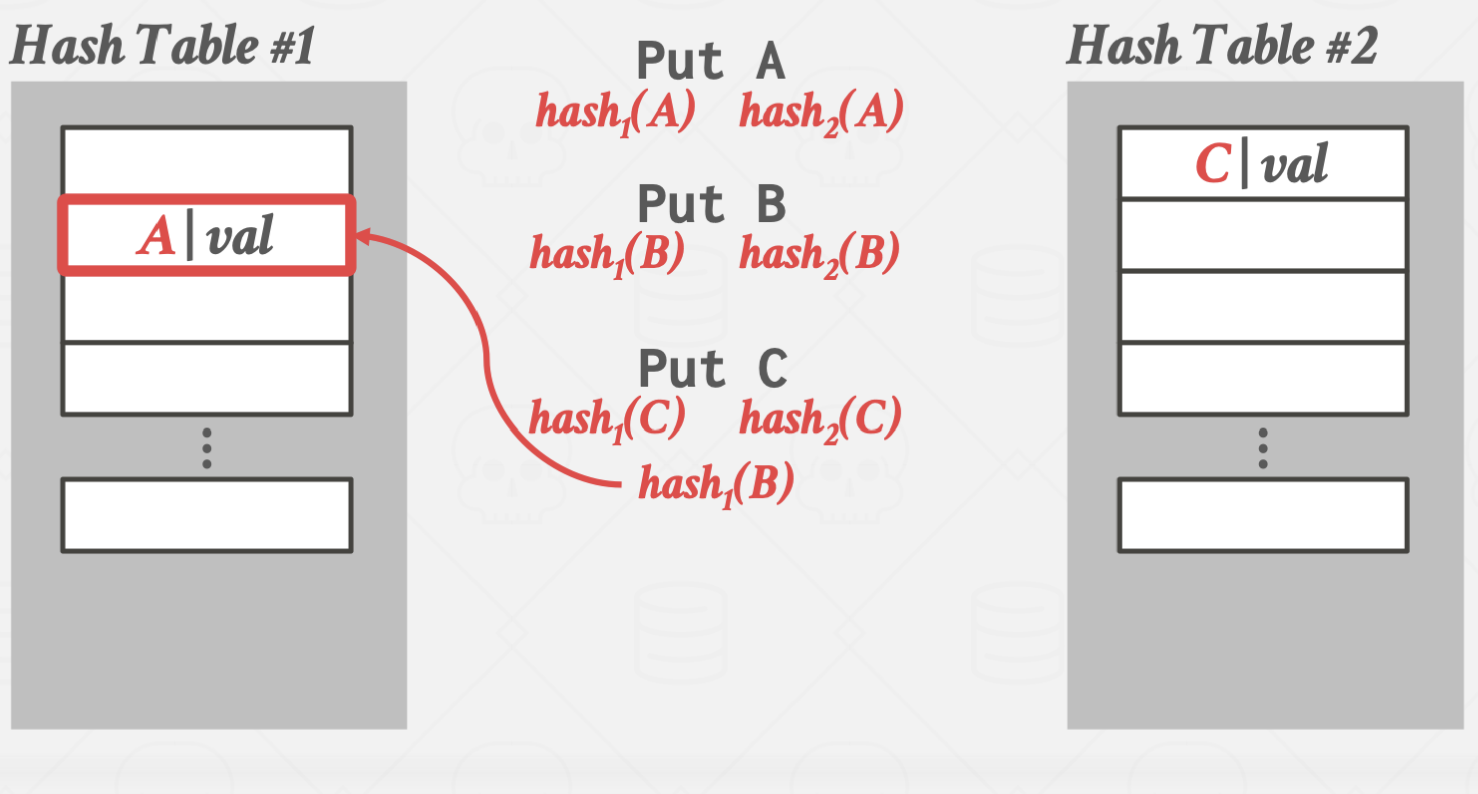
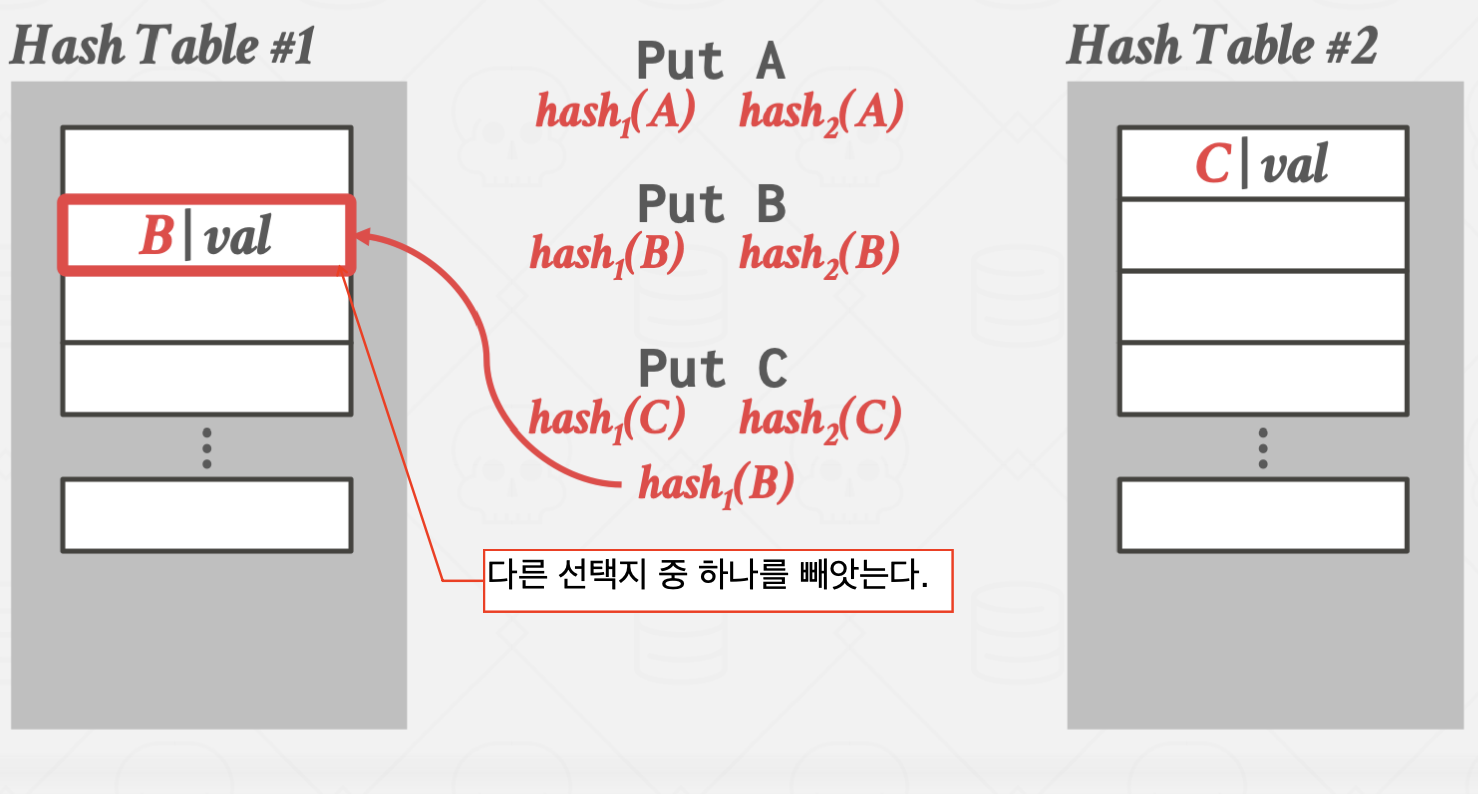
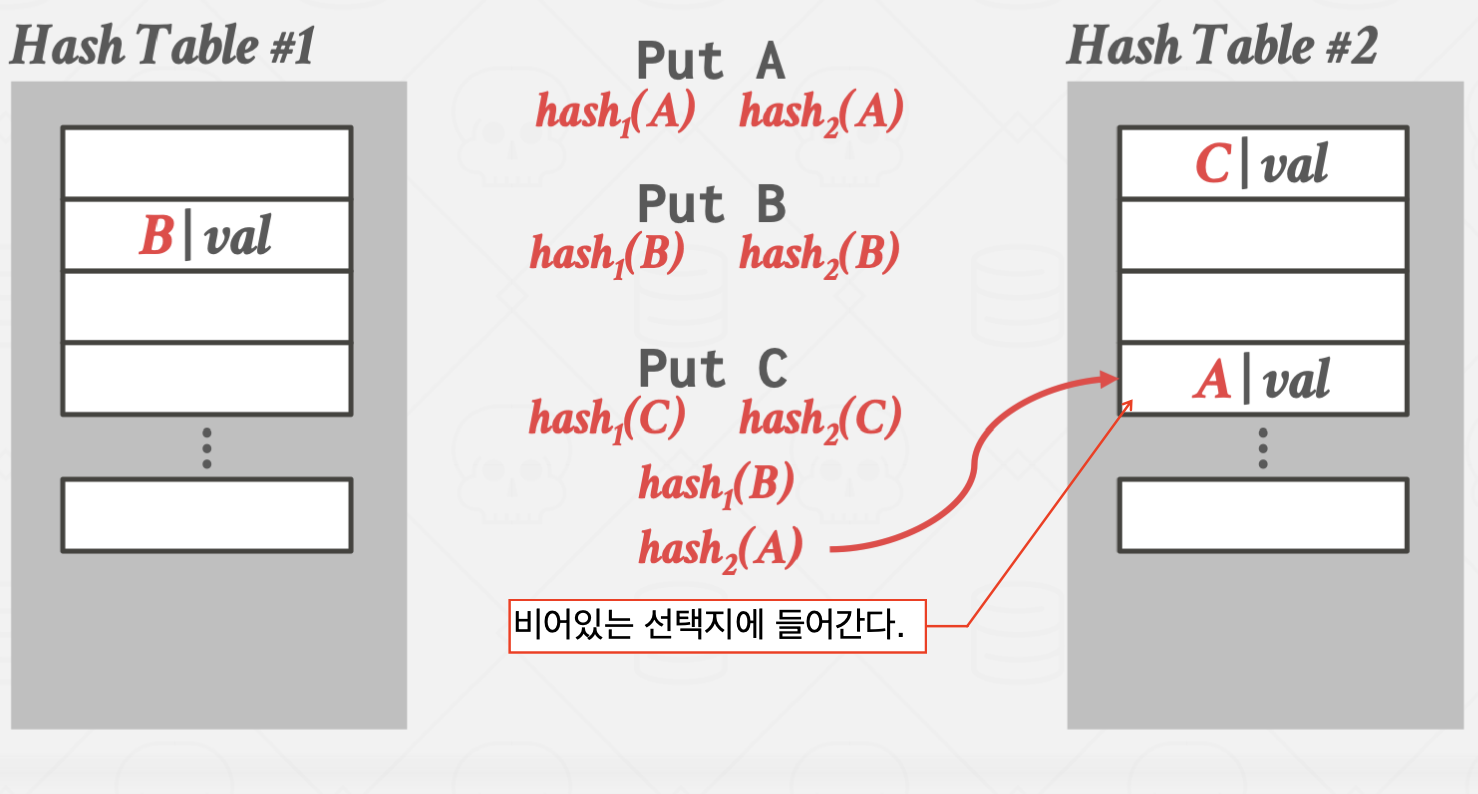
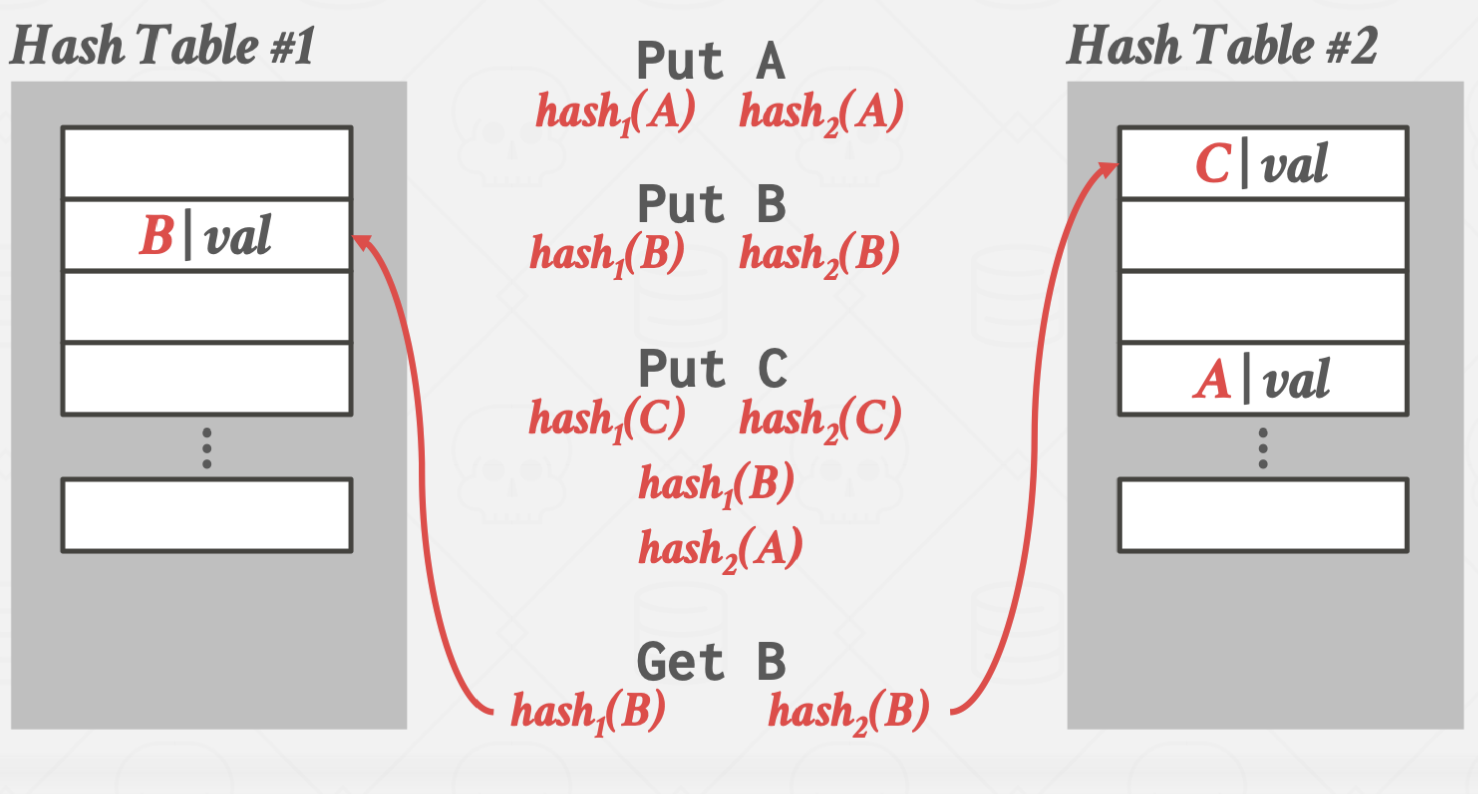
이 방법을 사용할 경우 해시 테이블 하나 당 단 한번의 해시 함수 연산만 있으면
원하는 값을 바로 찾을 수 있습니다.
하지만, key를 삽입할 때 마다 테이블을 추가로 할당해야 하고, 그 과정에서 오버헤드가 크기 때문에
삽입이 매우 어렵다는 단점이 있습니다.
이번엔 테이블이 가변적인 크기를 가질 때 사용할 수 있는 Hashing scheme 방법입니다.
- Chained Hashing
- Extendible Hashing
- Linear Hashing
Chained Hashing
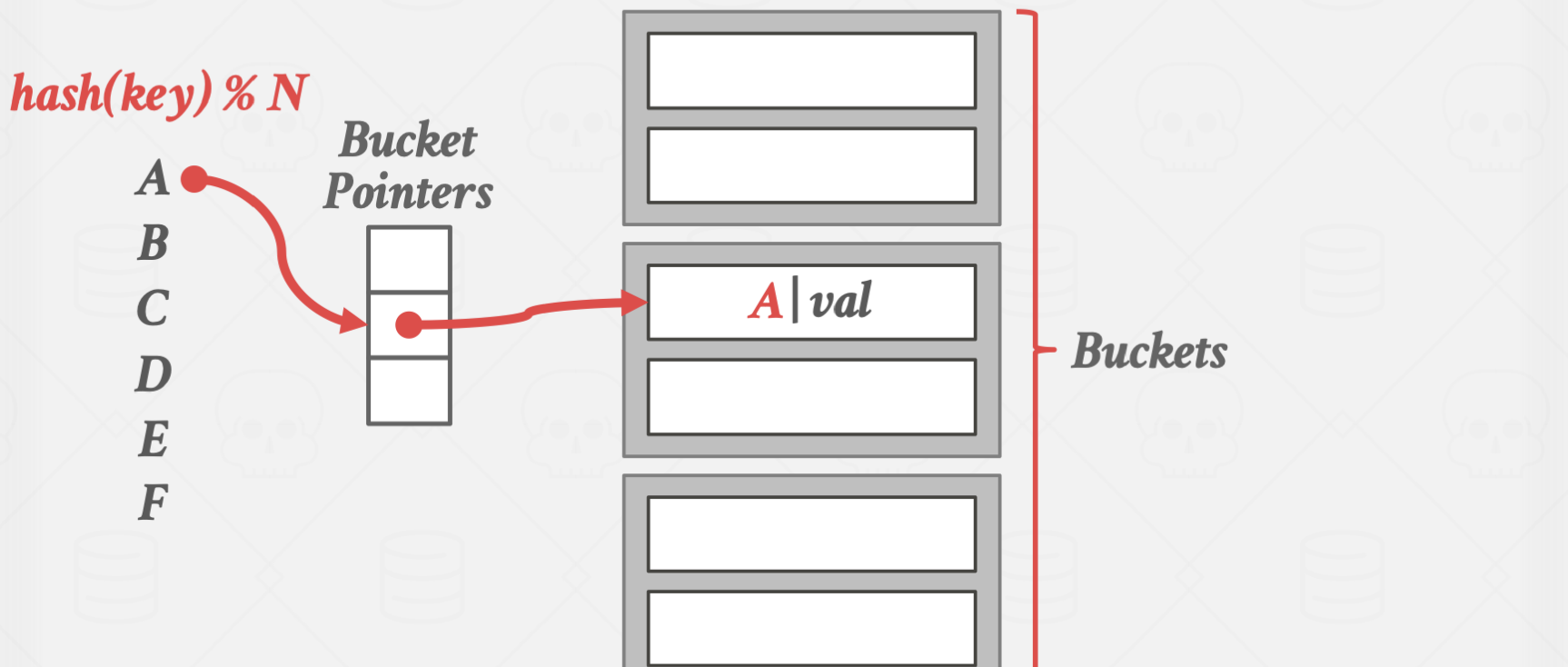
bucket 단위의 고정 길이의 슬롯 배열을 갖고, bucket potinter를 이용해서 특정 버킷을 가리킵니다.
특정 버킷이 가득 찬 경우에는 Linked List 형태로 다른 버킷을 연결해줍니다.
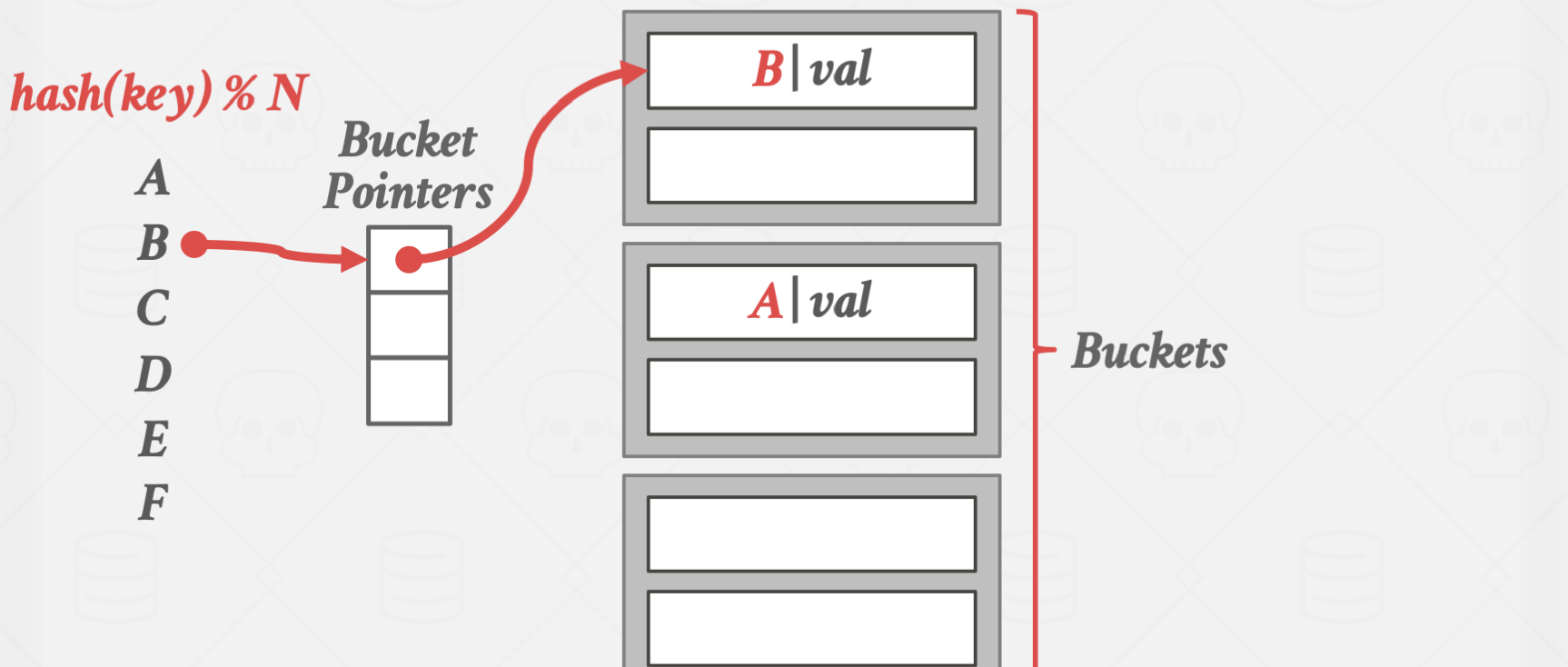

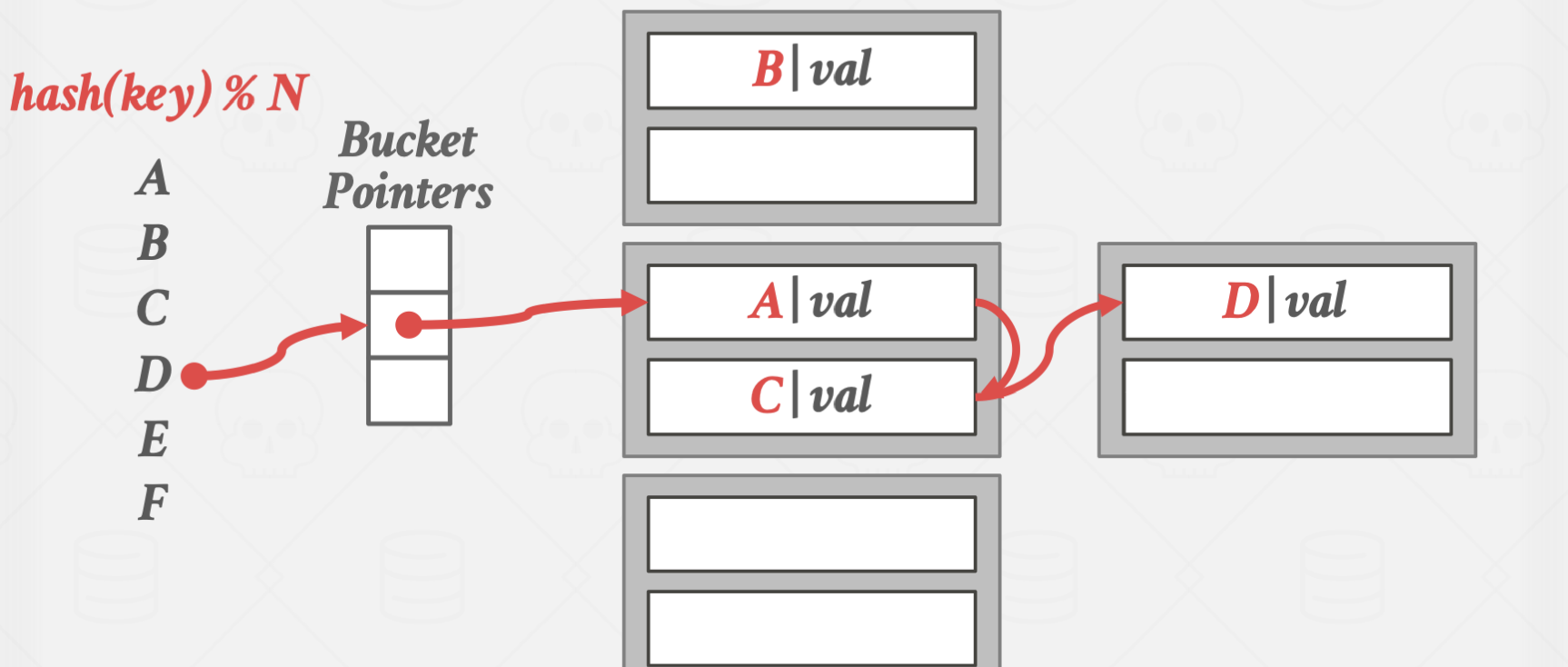


이 경우에는 장점이자 단점이 크기가 무한히 늘어난다는 점입니다.
크기가 무한히 늘어날 수 있기에 데이터 재배열의 오버헤드가 없지만,
탐색 시간이 무한히 길어질 수 있다는 치명적인 문제가 발생합니다.
Extendible Hashing
이 방법은 Chained Hashing의 단점인 탐색 시간이 무한히 길어진다는 단점을 완화한 방법으로
서로 다른 버킷 포인터가 같은 버킷을 가리킬 수 있지만,
확장하는 과정에서 다른 곳을 가리키도록 바꾸는 과정에서 약간의 오버헤드가 발생하지만,
탐색 과정을 획기적으로 줄일 수 있는 방식입니다.
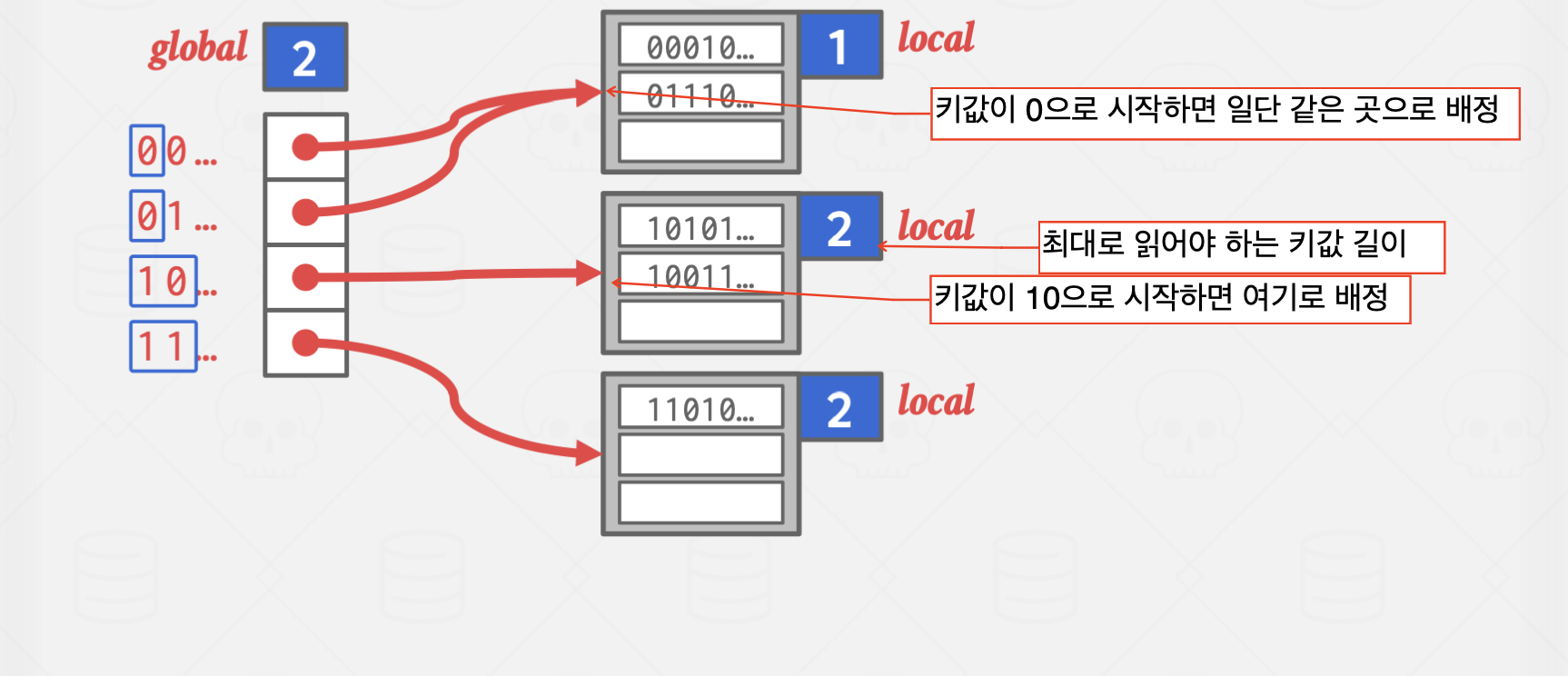
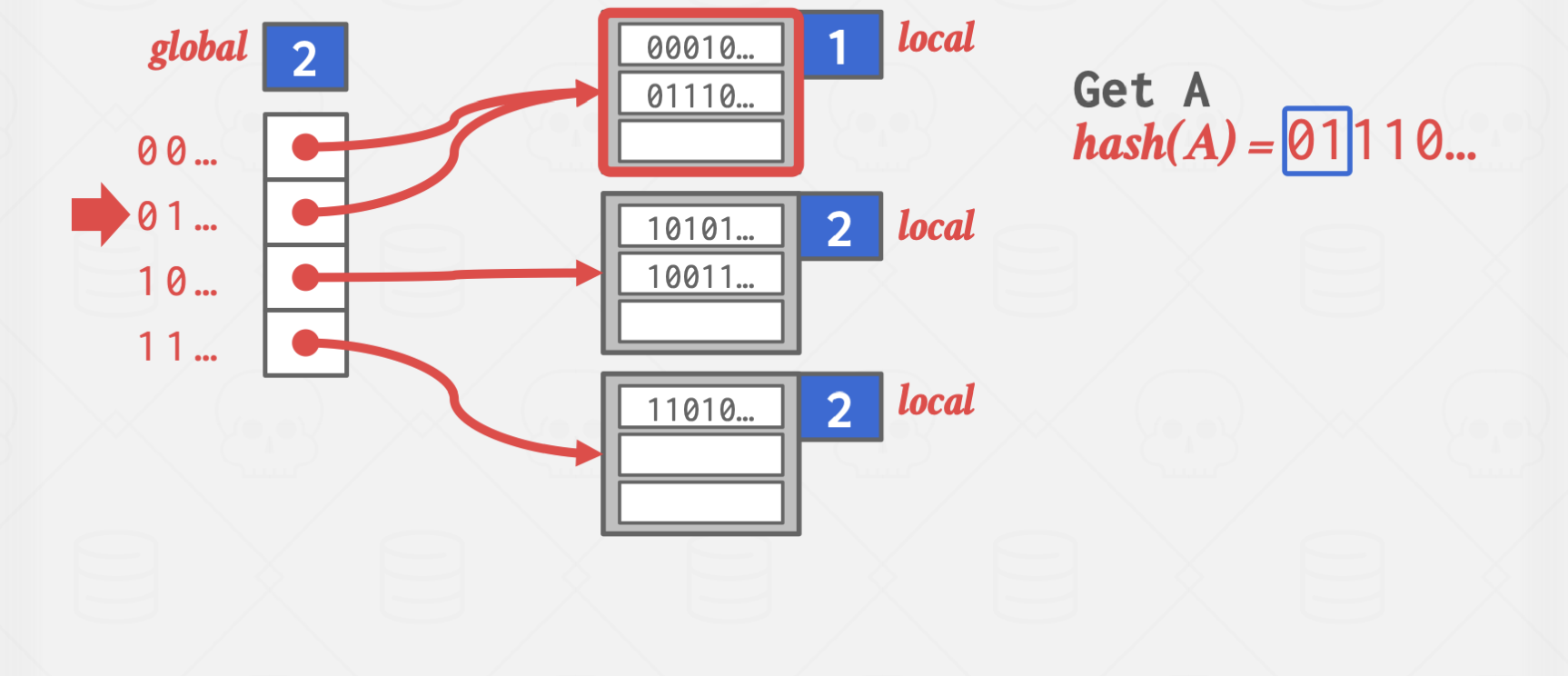
파란 박스의 값은 해시 함수의 결과값 중 버킷을 구분하기 위해 읽어야 할 자릿수를 의미합니다.
하이라이트 처리된 버킷은 앞에서 1자리,
즉, 0으로 시작하는 모든 key는 해당 버킷에 저장하는 방식입니다.

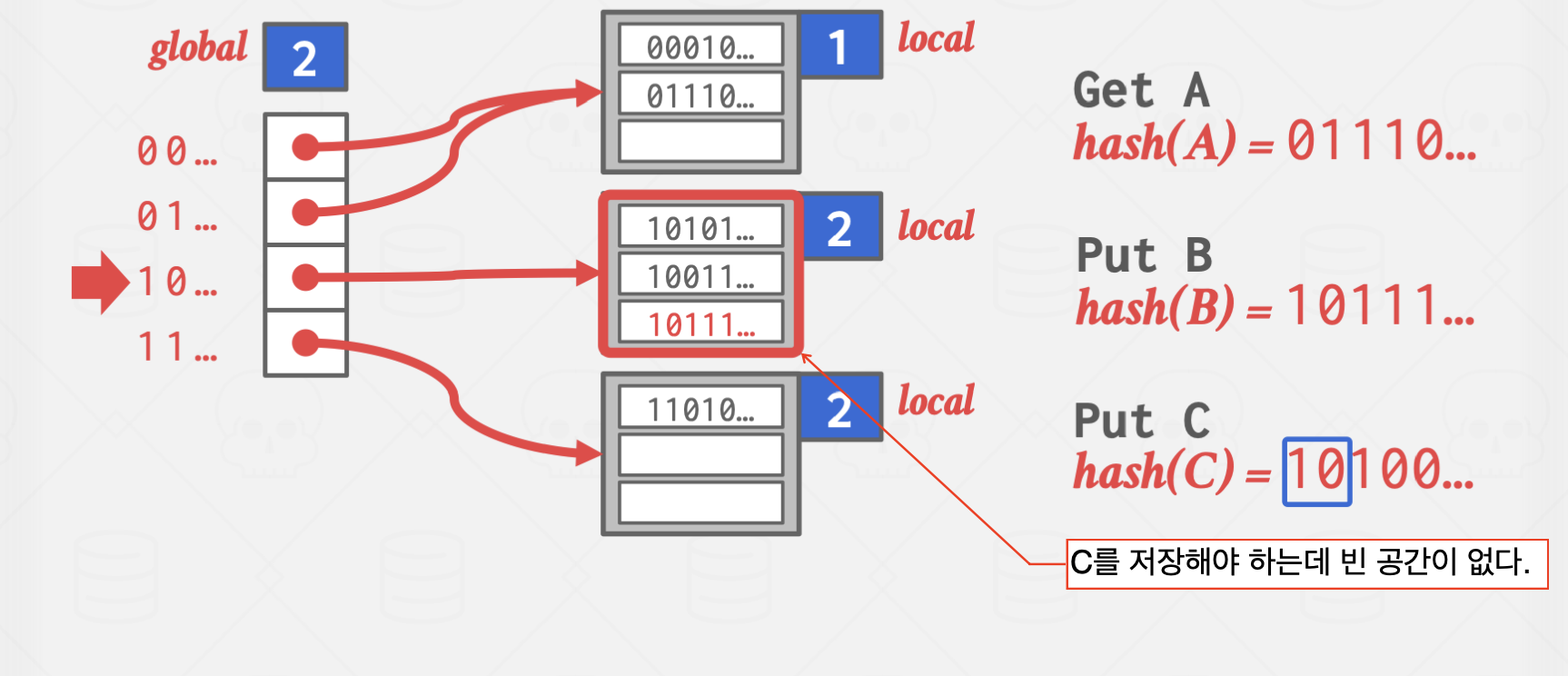
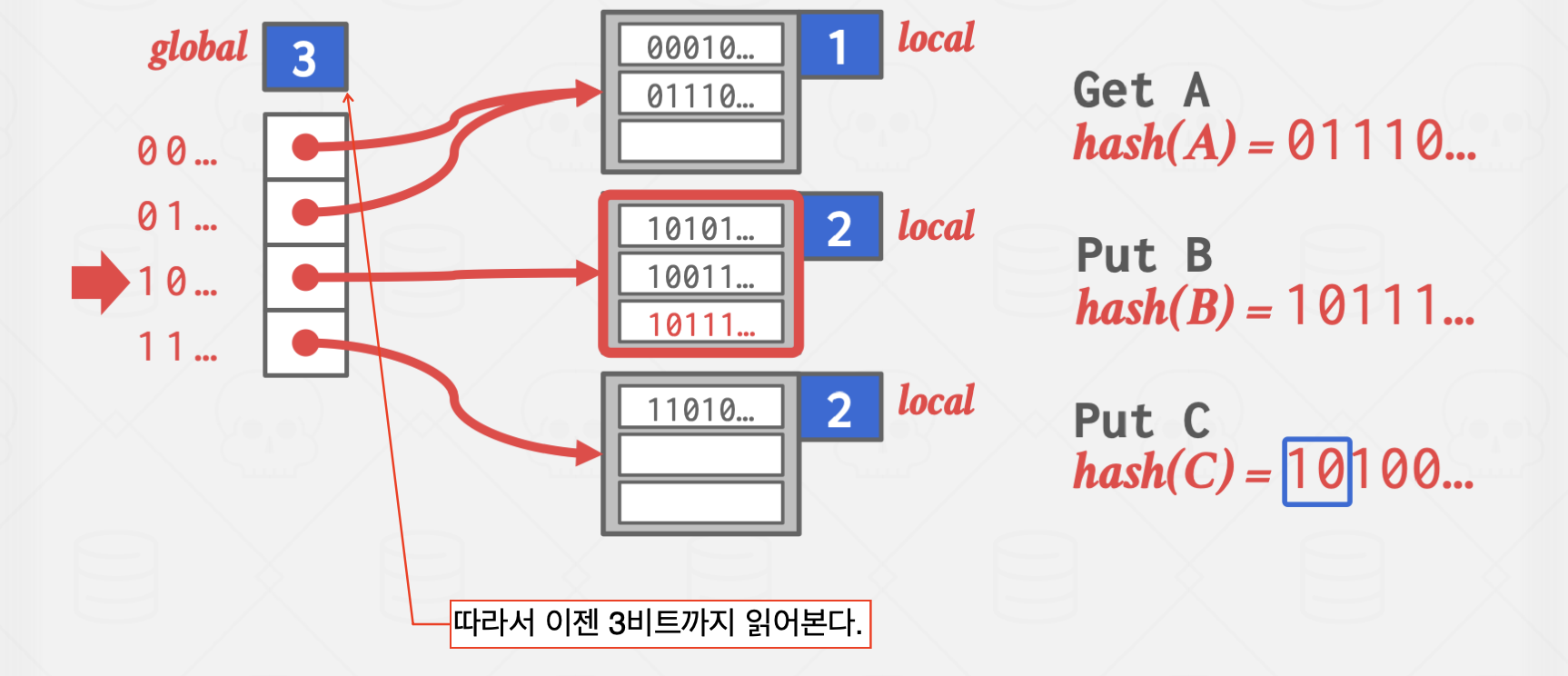
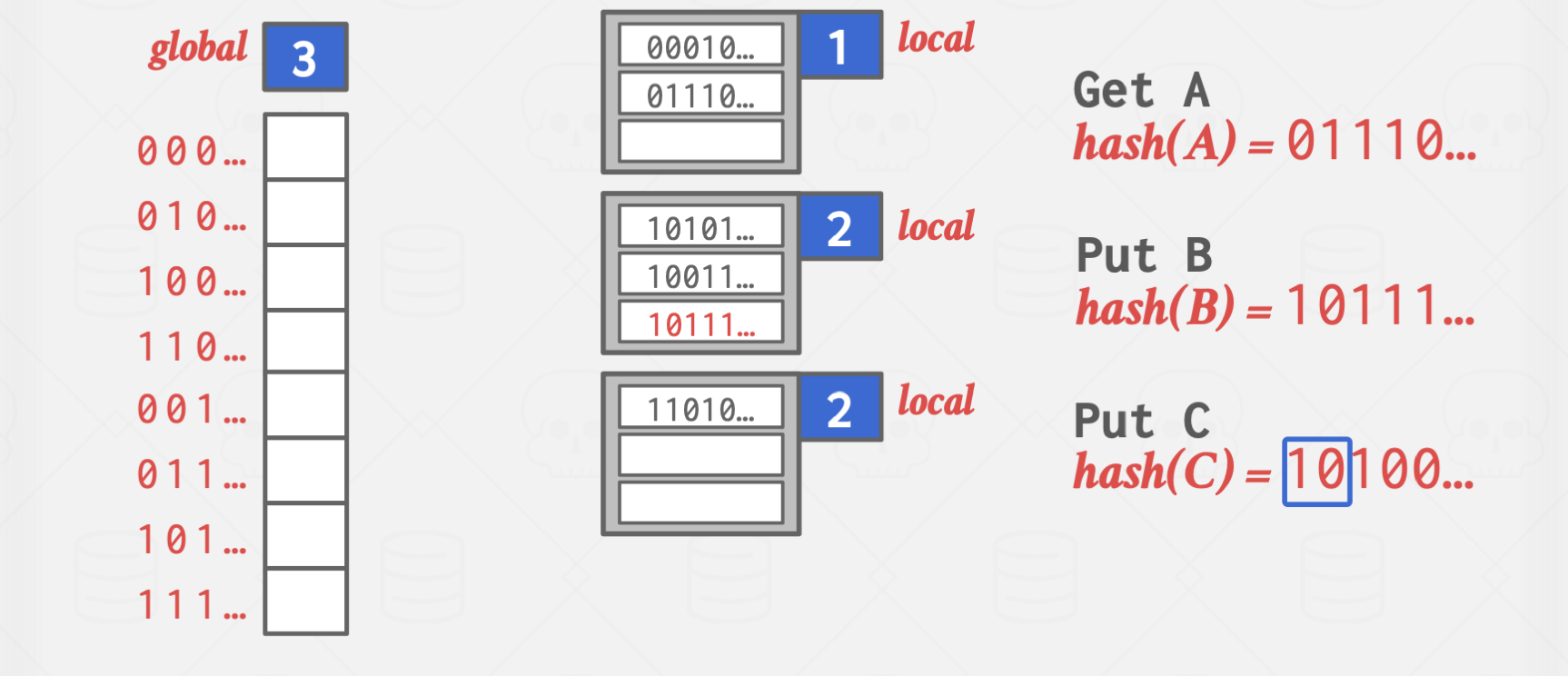
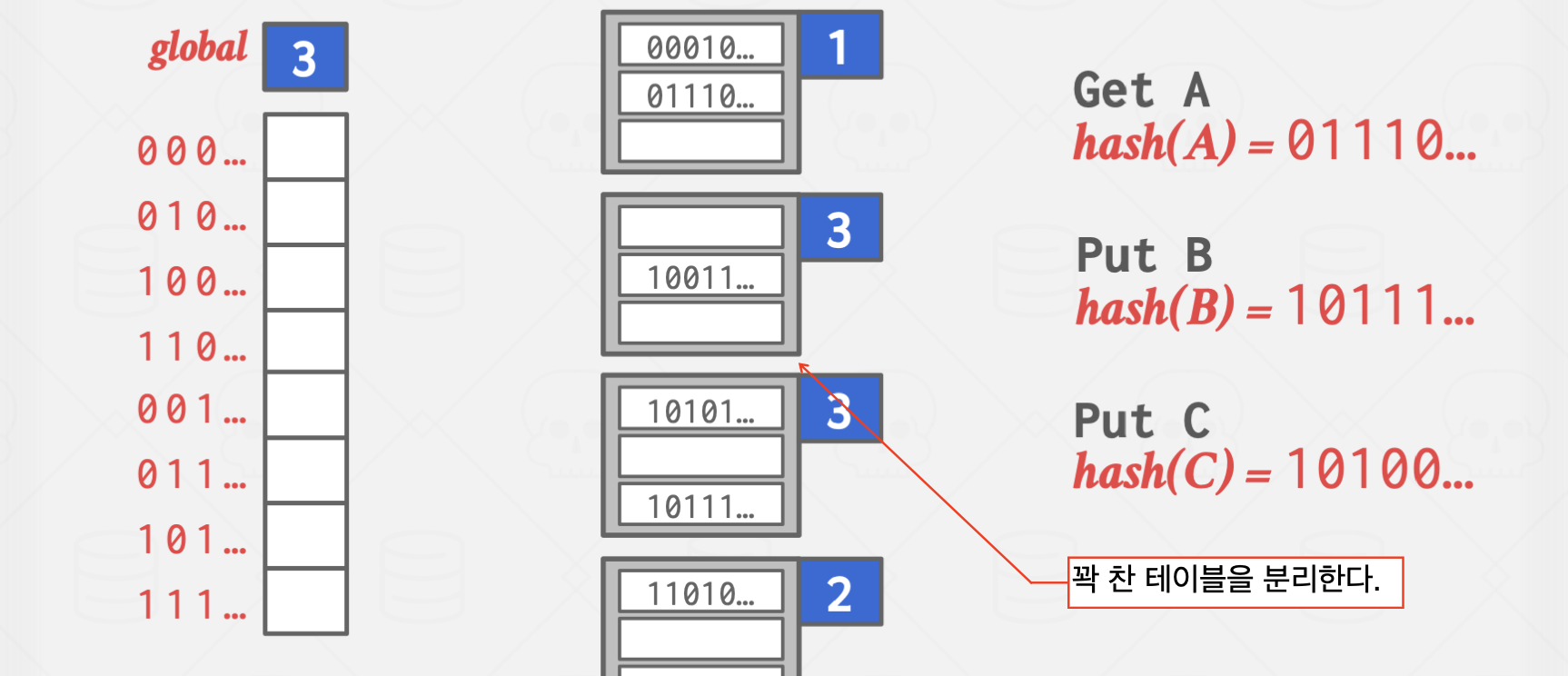
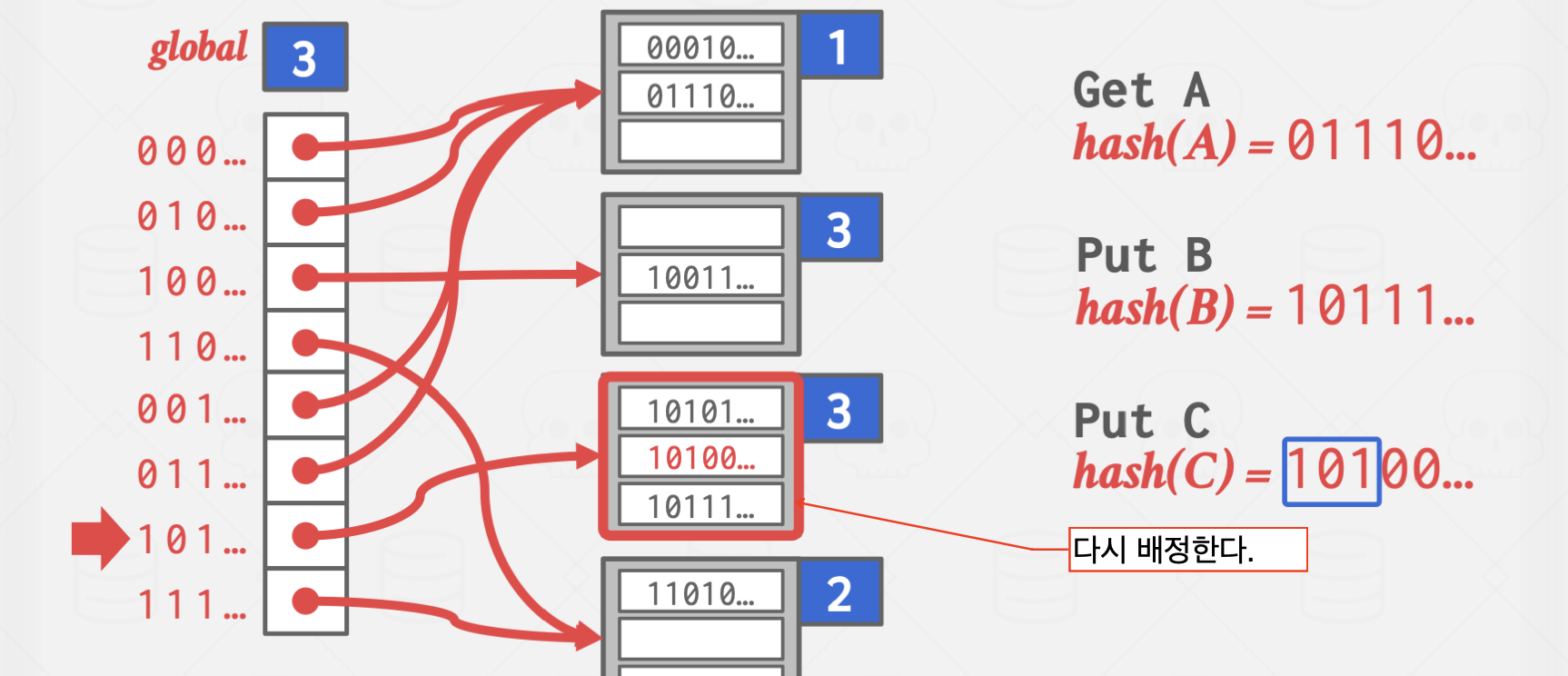
위 방식은 Overflow가 발생한 곳에 지속적으로 값이 들어오는 상황에서 유효합니다.
Linear Hashing
이 방식은 좀 비상식적인 방식으로 작동합니다.
Overflow가 발생한 곳을 split하지 않고, split pointer가 가리키는 곳을 split 하는 방식으로 작동합니다.
이를 통해 Overflow Chain의 길이를 일정하게 유지시키는 효과가 있습니다.
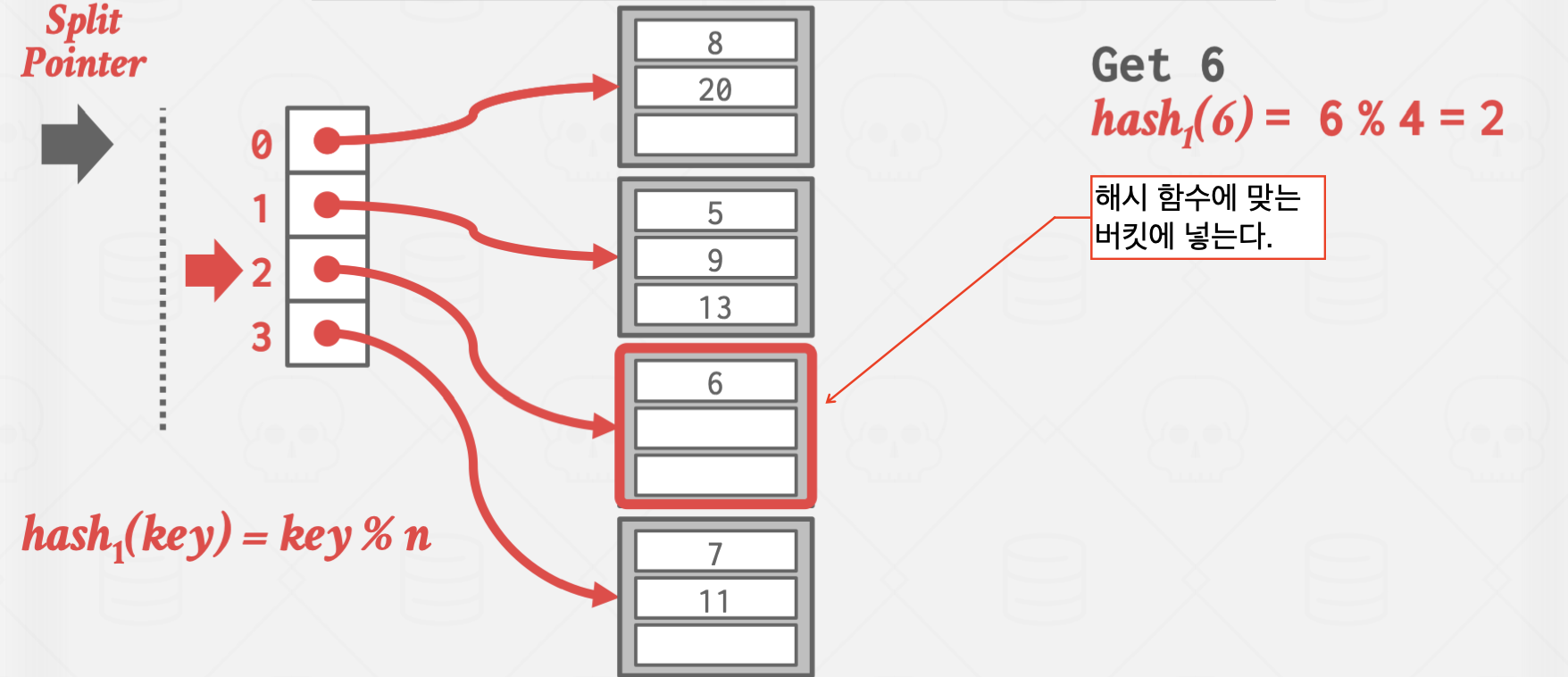
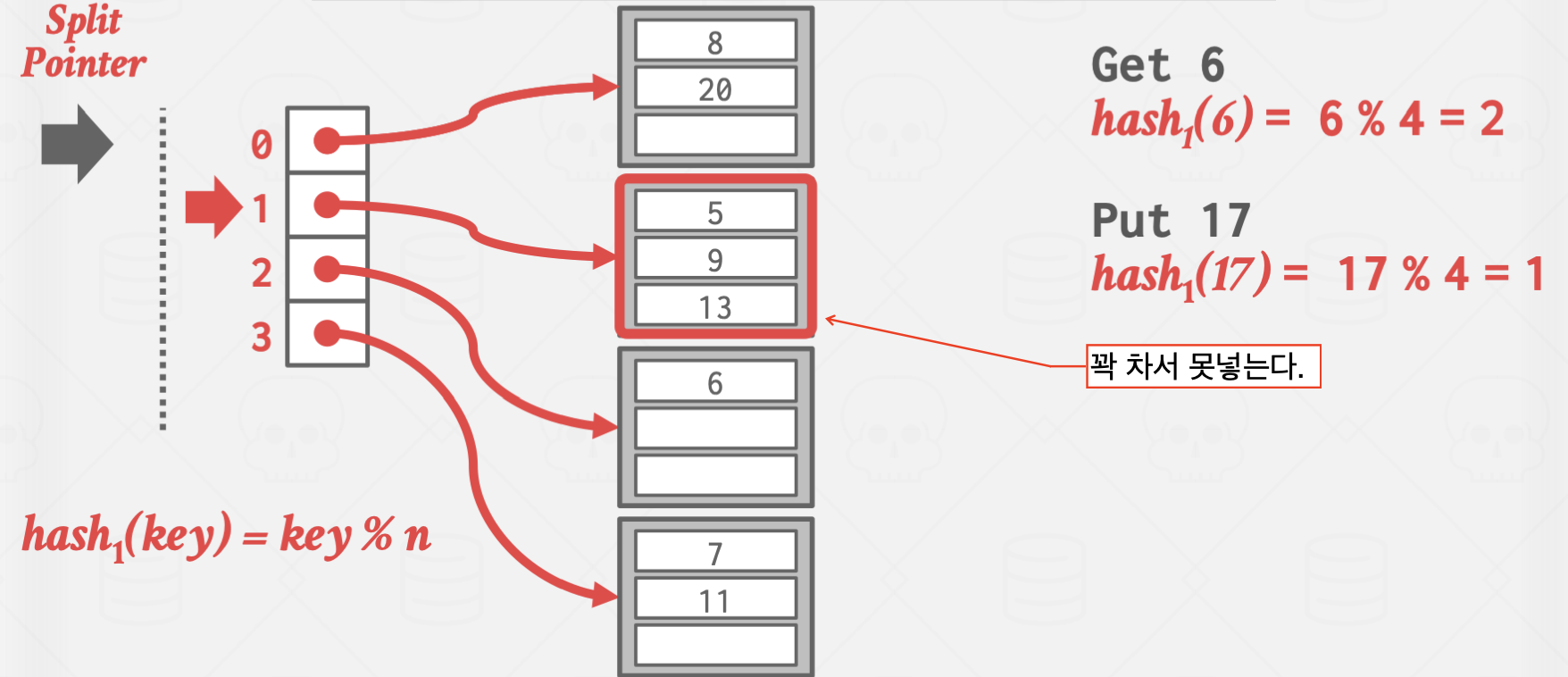
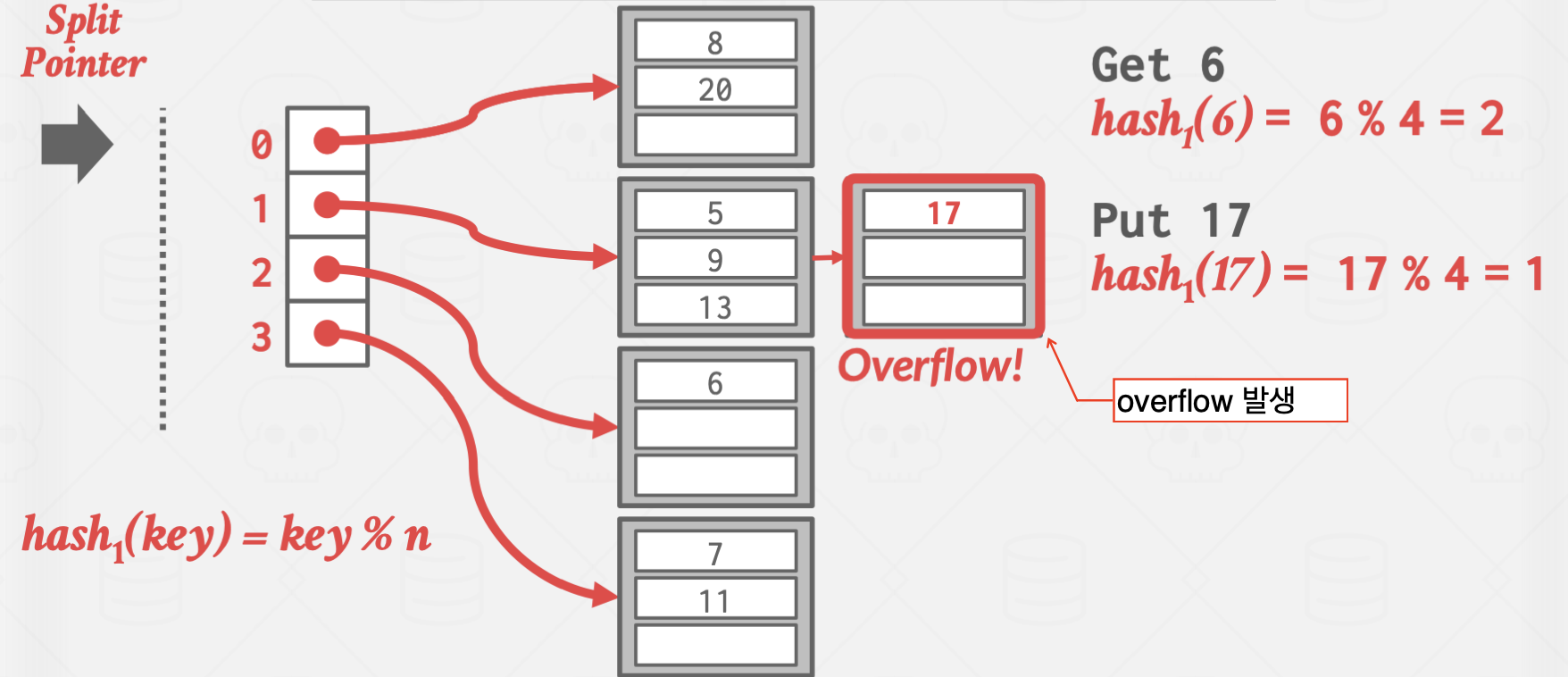
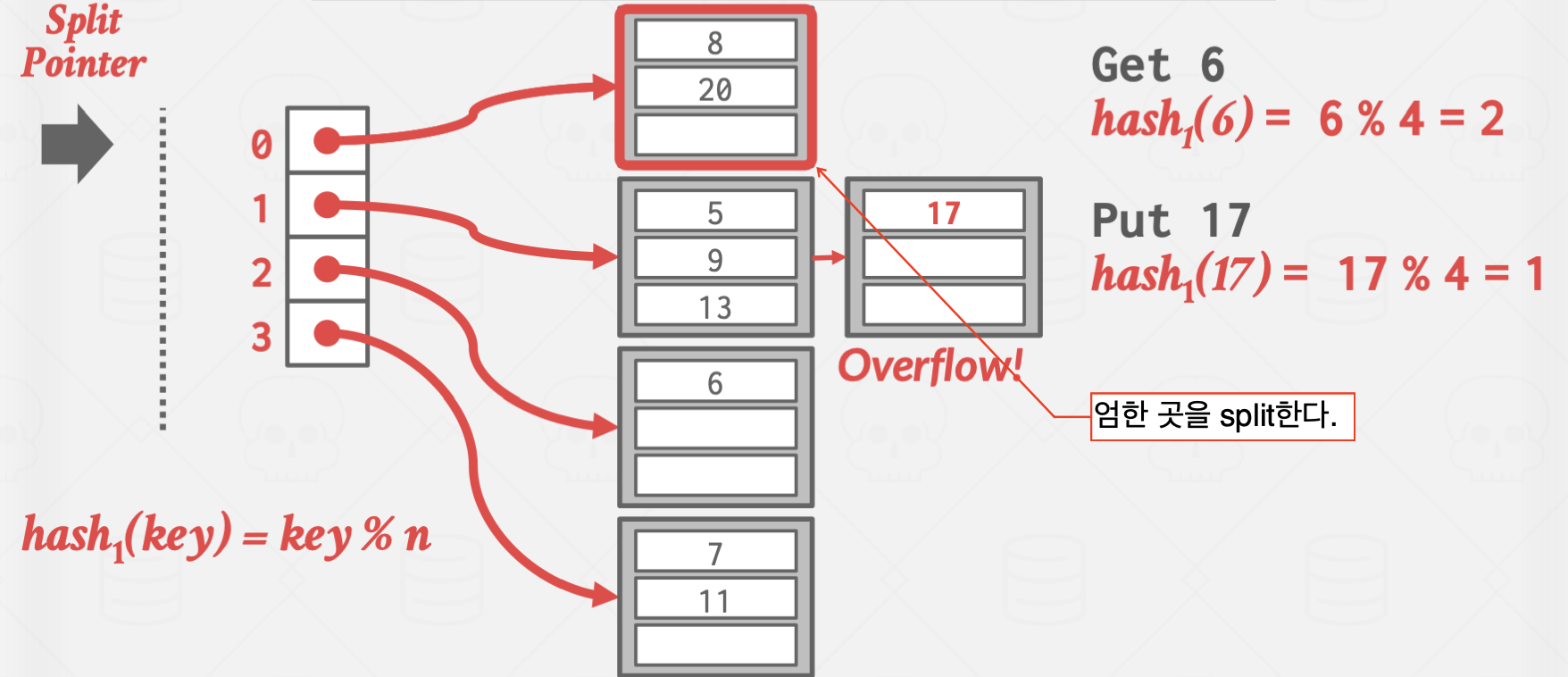
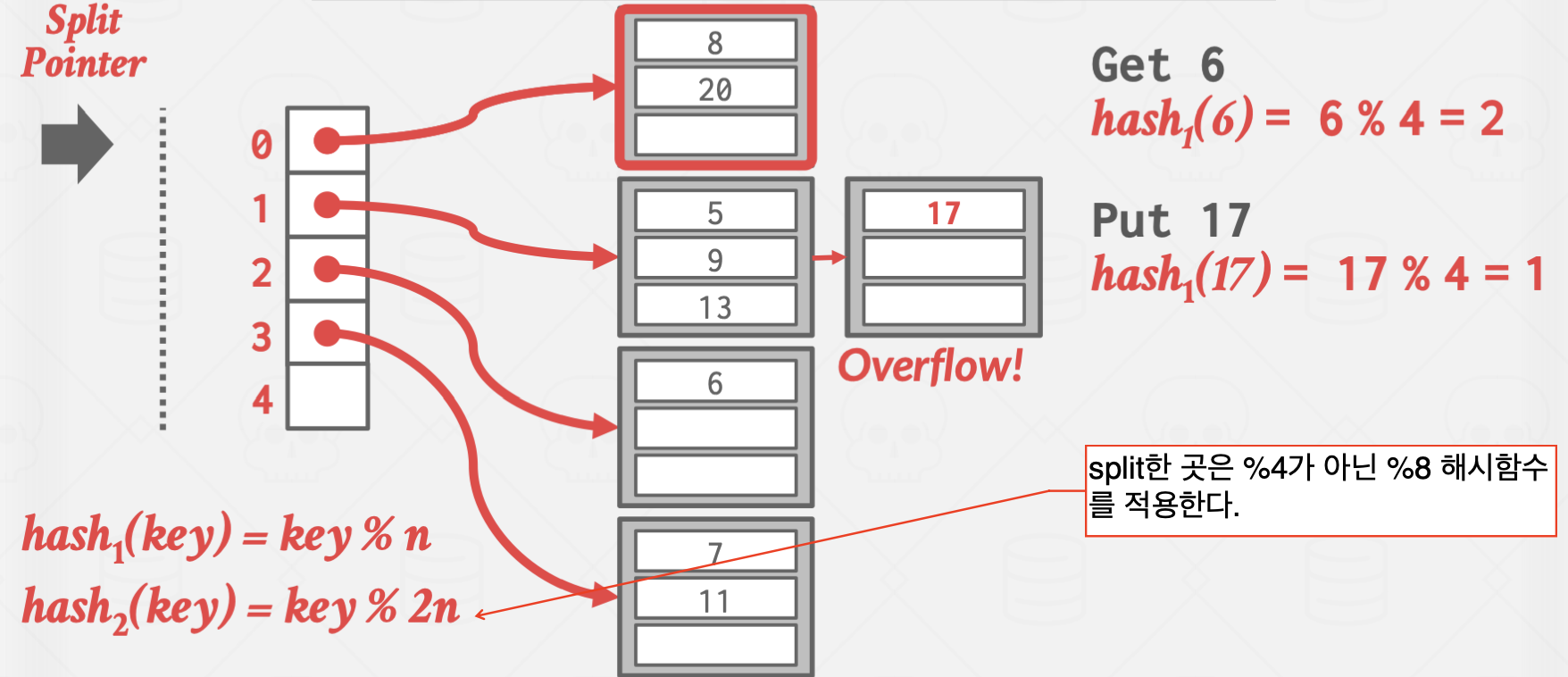
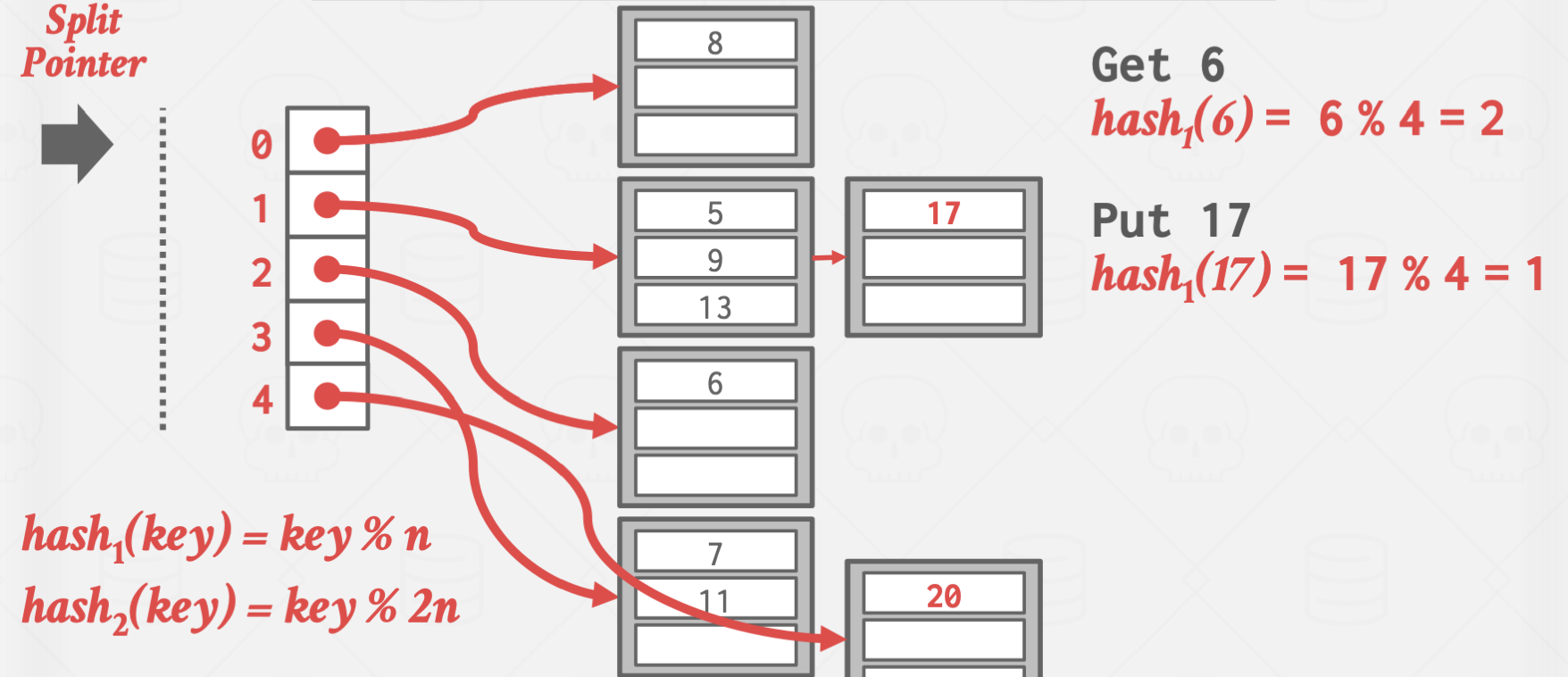
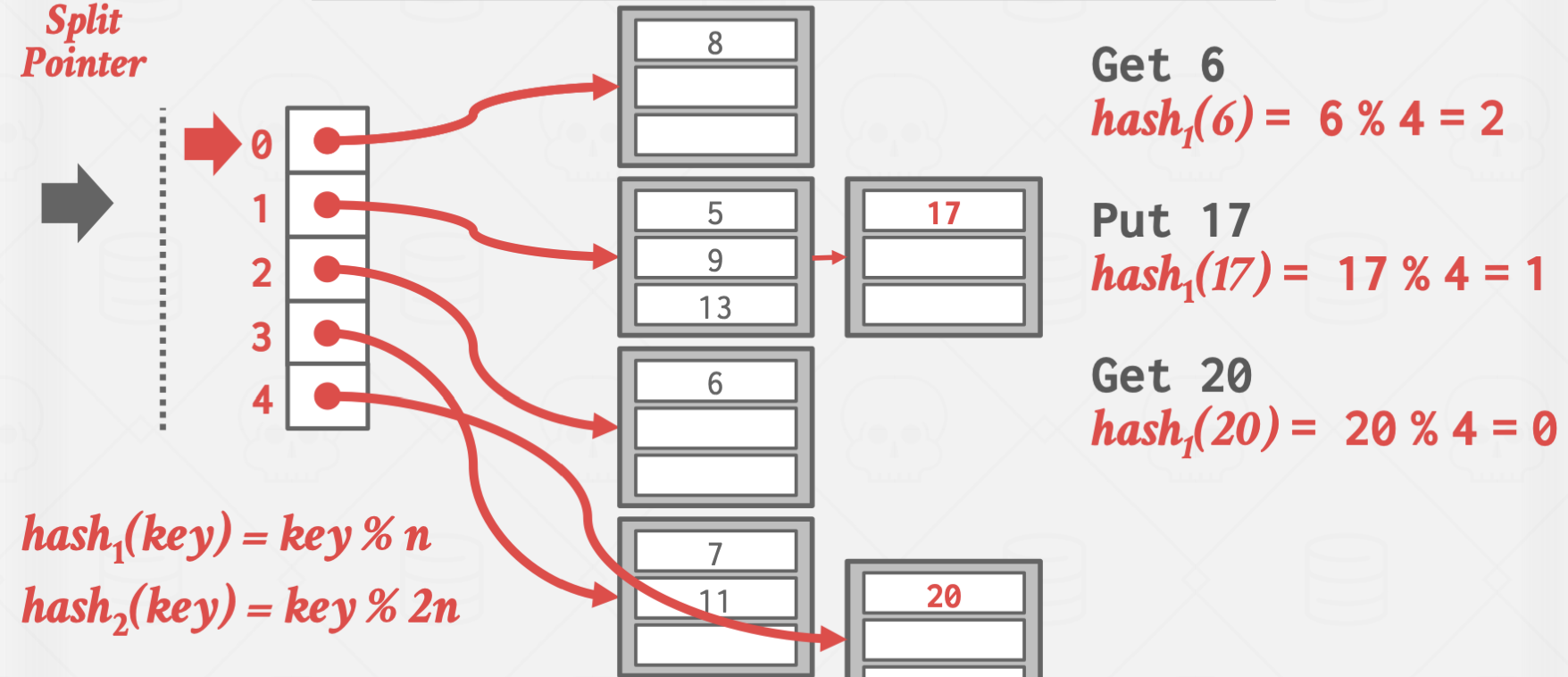
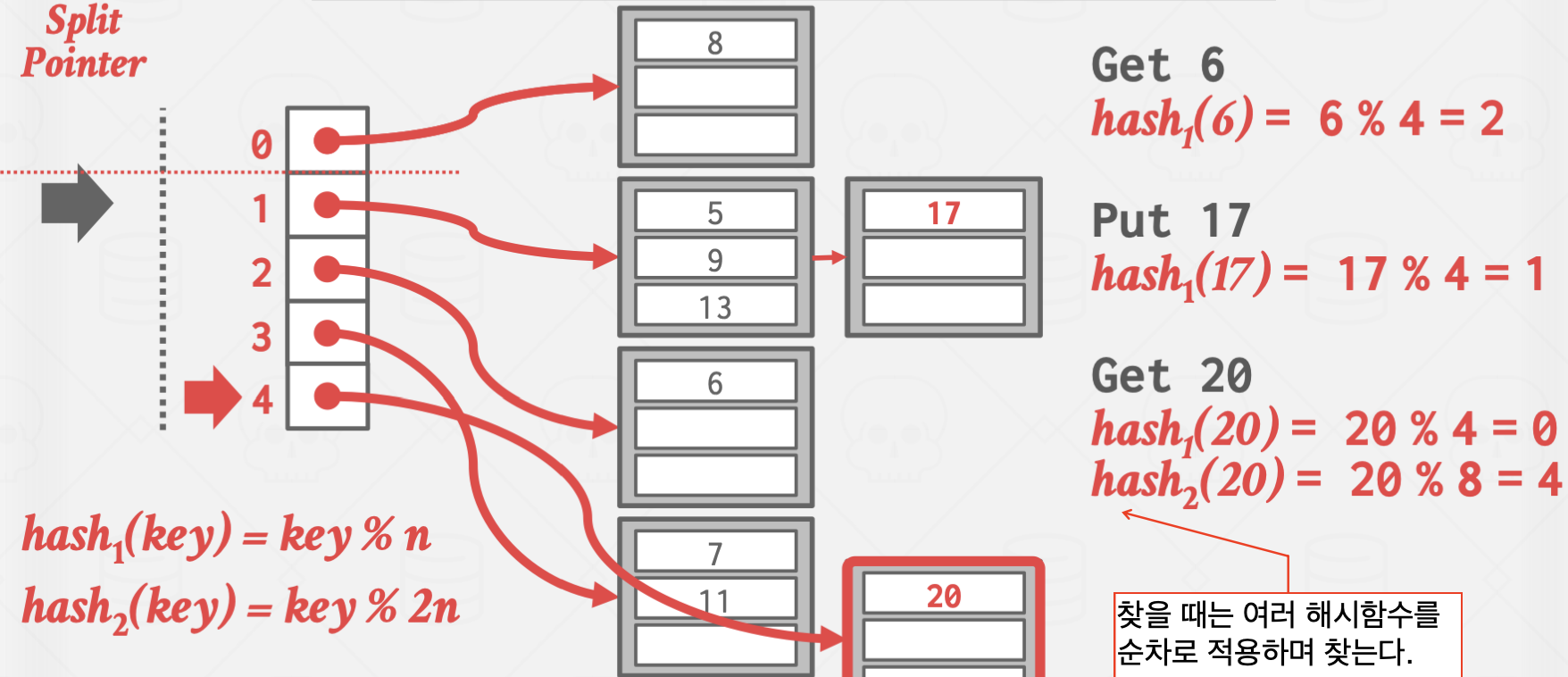
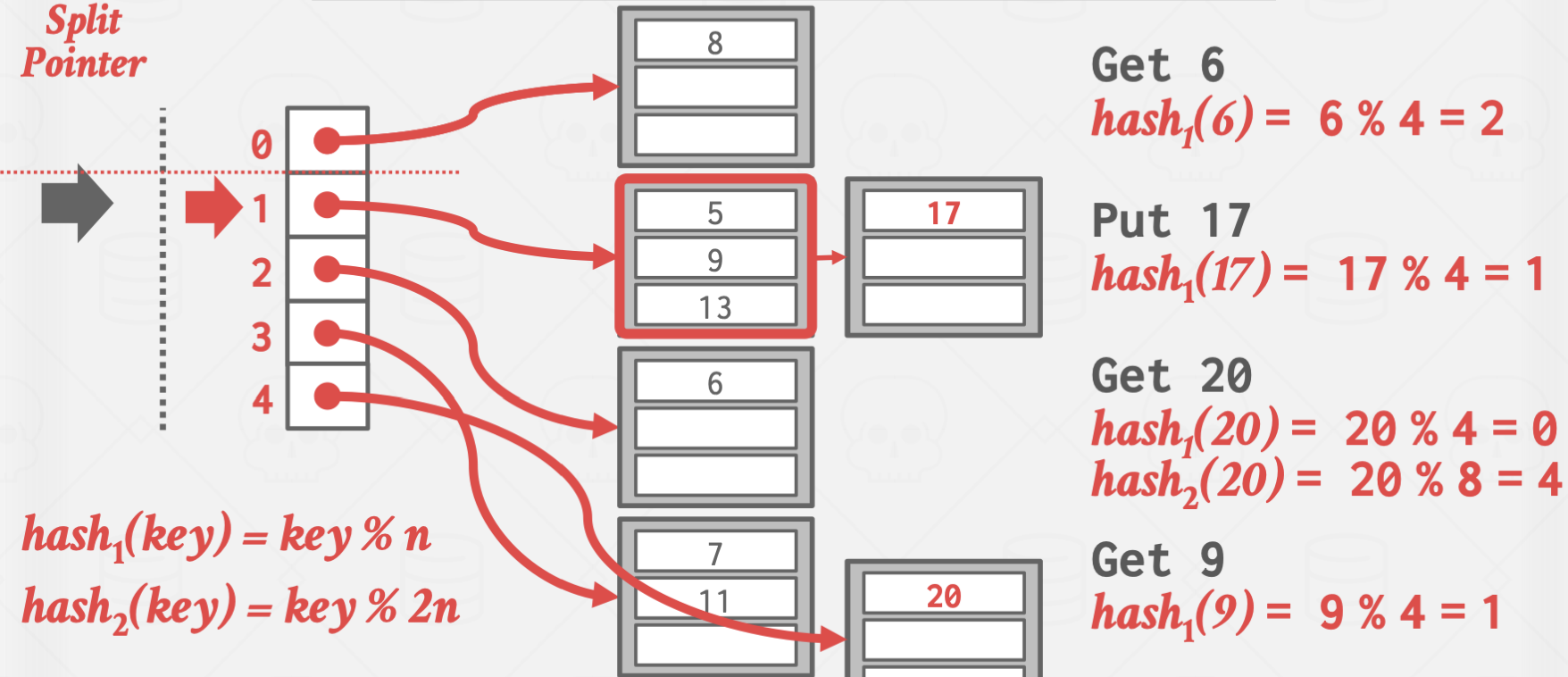
위 방식은 Overflow가 발생한 곳은 값이 잘 들어지 않는 상황에서 유효합니다.
'대학 > 데이터베이스' 카테고리의 다른 글
Query Processing (0) 2023.06.04 DBMS - B+Tree (0) 2023.06.04 Database Storage (2) 2023.06.03 Normalization (0) 2023.06.03 Database Design using E-R model (0) 2023.04.15