-
Linked list대학/자료구조 2022. 10. 17. 21:29
연결 리스트는 배열과 물리적인 구조부터 다르다.
일반 배열은 물리적인 메모리 공간이 붙어있기 때문에, 배열의 첫 번째 주소만 알면, 특정 인덱스의 메모리에 빠르게 접근할 수 있다.
즉, Random access가 가능하다. (n번째 인덱스 = 배열 첫번째 주소 + n)
하지만 배열의 공간이 한정되어 있기 때문에, 공간이 꽉 찰 경우 에러를 발생시키거나 배열의 공간을 동적으로 늘려줘야 한다.
그 이후 데이터를 복사를 해야하기 때문에, 데이터 추가의 측면에서 성능이 좋지 못하고, 메모리 공간을 효율적으로 쓸 수 없다.
연결 리스트의 경우에는 이런 배열의 특성과 반대되는 특성을 갖는다.
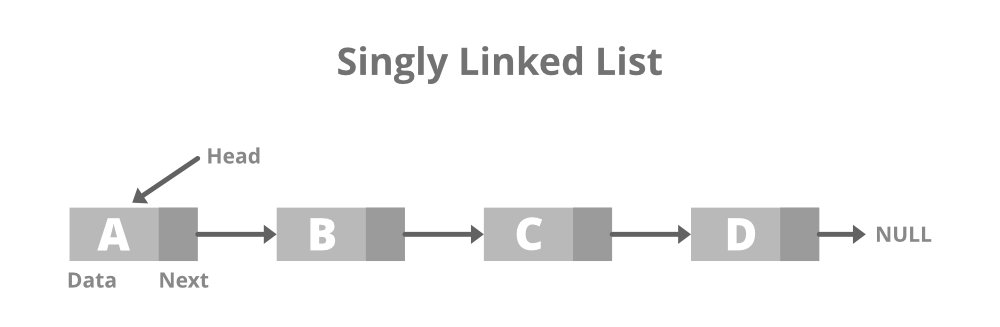
<Fig. 01: Singly linked list> 연결 리스트는 물리적인 메모리 공간이 떨어져 있고, 각 메모리 공간이 다음 메모리 공간을 가르킨다.
따라서 배열에서는 가능한 Random access가 불가능하다. (특정 데이터를 찾기 위해선 순차 검색을 해야한다)
하지만, 배열과 달리 공간이 한정되어 있지 않기 때문에,
새로운 데이터가 들어오면 동적으로 할당 받고, 제거 시 동적으로 삭제가 되기 때문에,
데이터 추가의 속도가 빠르고, 메모리 공간을 효율적으로 사용할 수 있다는 장점이 있다.
따라서 이번에는 이런 연결 리스트를 이용해 앞서 만들었던 가방을 만들어 보도록 하자.
기본적인 가방 클래스의 선언은 아래 코드와 같다.
class node { public: typedef double value_type; node(const value_type& init_data = value_type(), const node* init_link = NULL); void set_data(const value_type& new_data); void set_link(node* new_link); value_type data() const; const node* link() const; node* link(); ... private: value_type data_field; node *link_field; };가방의 기능을 구하기 위해 기초적인 연결 리스트의 기능을 구현할 노드 클래스
class bag { public: typedef std::size_t size_type; bag(); bag(const bag& source); ~bag(); ... private: node *head_ptr; // List head pointer size_type many_nodes; // Number of nodes on the list };노드 클래스의 헤더 파일을 include하여 구현할 가방 클래스
- node class
우선 노드 클래스의 생성자부터 구현해보자.
node::node(const value_type& init_data, const node* init_link) { data_field = init_data; link_field = (node *)init_link; }참고로 구현 목적은 가방 클래스를 구현하는 것 이기 때문에, 노드 클래스에서 따로 파괴자 함수는 구현하지 않았습니다.
data_field에는 저장할 데이터를, link_field에는 다음 노드를 가리키는 포인터를 저장한다.
특이한 점은 위의 선언 파일에서 init_data의 초기 값을 값이 아닌, value_type() 과 같은 함수 형태로 지정해 줬다는 것인데,
사실 value_type()은 함수가 아니라, 익명의 value_type객체를 만들어서 넣어주겠다 라는 뜻이다.
값이 아닌 객체를 넣어주는 이유는, const reference parameter는 변수를 인자로 넣어줘야 하기 때문이다.
다음은 노드 클래스의 getter 함수를 구현해보자.
value_type node::data() const { return data_field; } const node* node::link() const { return link_field; } node* node::link() { return link_field; }data()는 현재 노드가 저장하고 있는 데이터를 리턴하고, link()는 현재 노드가 가리키고 있는 노드의 포인터를 리턴한다.
여기서 눈여겨 봐야 할 점은, link() 함수가 두 개 정의되어 있다는 것인데,
만약, node 객체가 const로 생성된다면, 그 객체가 link() 함수를 호출시 위의 함수가 호출되고,
node 객체가 const 없이 생성된다면, 그 객체가 link() 함수를 호출시 아래의 함수가 호출되게 된다.
node* link() { return link_field; } node *second = head_ptr->link( ); second->set_data(9.2); const node* link() const { return link_field; } const node *second = head_ptr->link( ); second->set_data(9.2); // Error!!위 코드는 사용 예시이다.
다음은 노드 클래스의 길이를 반환하는 함수를 구현해보자.
size_t list_length(const node *head_ptr) { size_t answer = 0; const node *cursor; for (cursor = head_ptr; cursor != NULL; cursor = cursor->link()) { answer++; } return answer; }cursor는 인자로 입력받은 head_ptr부터 head_ptr이 가리키고 있는 노드로 이동하며 순차적으로 모든 노드를 탐색하게 된다.
노드가 가리키고 있는 다음 노드가 없다면, 반복문을 종료하게 되고,
반복문이 수행된 횟수가 노드의 연결 개수가 된다.
다음은 노드 클래스에서 맨 앞에 데이터를 추가하는 함수를 구현해주자.
void list_head_insert(node *&head_ptr, const node::value_type &entry) { head_ptr = new node(entry, head_ptr); }새로운 노드를 생성자 함수를 통해 만들어준다.
인자로 저장할 값 entry와 연결할 node의 포인터 head_ptr을 넘겨준다.
새로 만들어질 노드 생성자의 인자를 head_ptr로 넣어주어, 새로 만들어진 노드->link()는 head_ptr을 가리키게 된다.
참고로, head_ptr를 reference 타입으로 넘겨받았기 때문에 함수 내부에서 변경되는 값은 외부에도 적용된다.
따라서, 함수 내부에서 head_ptr의 포인터 값을 새로 만드는 node 객체의 포인터 값으로 바꿔주면,
새로 만들어진 노드(head_ptr로 새로 바뀜)->head_ptr(기존 head_ptr)->다음 node 이런 식으로 연결이 완성된다.
다음은 노드 클래스에서 특정 위치에 데이터를 추가하는 함수를 구현해보자.
void list_insert(node *previous_ptr, const node::value_type &entry) { node *insert_ptr; insert_ptr = new node; insert_ptr->set_data(entry); insert_ptr->set_link(previous_ptr->link()); previous_ptr->set_link(insert_ptr); /** * // Single line code * previous_ptr->set_link(new node(entry, previous_ptr->link())); */ }중간에 넣어줄 insert_ptr 노드 객체를 하나 만들어주고,
data_field를 set_data() 함수를 이용해 entey로 넣어주고,
link_field를 set_link() 함수를 이용해 이전 노드가 가리키고 있던 노드의 포인터 값으로 넣어준다.
이렇게 하면, previous_ptr, insert_ptr 모두 다음 node를 가리키게 되는데,
이 때, previous_ptr이 가리키는 노드를 insert_ptr로 바꿔주면,
previous_ptr->insert_ptr->다음 node 이런식으로 연결이 완성된다.
list_head_insert 함수와 다르게 previous_ptr를 넘겨줄 때 reference 타입이 아닌 그냥 value 타입으로 넘겨준 이유는
가방 클래스를 구현할 때, 가방의 연결 리스트의 처음을 가리키는 포인터는 head_ptr이 바뀌면
처음을 가리키는 포인터 역시 바뀌여야 하기에 reference 타입으로 구현해 줬지만,
중간에 끼워넣는 list_insert 함수의 경우에는 가방의 연결 리스트의 처음을 가리키는 포인터의 값에는 변화가 없어야 하고,
물론 호출시 인자로 넘겨주는 previous_ptr도 변경할 이유가 없기 때문이다.
(단, 포인터로 넘겨줬기 때문에 함수 내부에서 previous_ptr 노드의 내용은 바꿀 수 있다)
다음은 노드 클래스에서 인자로 들어온 노드 부터 검색하여 특정 데이터가 포함된 첫 번째 노드를 반환하는 함수를 구현해보자.
node *list_search(node *head_ptr, const node::value_type &target) { node *cursor; for (cursor = head_ptr; cursor != NULL; cursor = cursor->link()) { if (target == cursor->data()) { return cursor; } } return NULL; } const node *list_search(const node *head_ptr, const node::value_type &target) { const node *cursor; for (cursor = head_ptr; cursor != NULL; cursor = cursor->link()) { if (target == cursor->data()) { return cursor; } } return NULL; }두 개를 만들어준 이유는, 선언한 node가 const 타입일 수도 아닐 수도 있기 때문이다. (노드 클래스의 getter 함수와 같은 이유)
노드 클래스의 길이를 반환해주는 함수와 마찬가지로 cursor가 head_ptr부터 head_ptr이 가리키는 노드를
계속해서 순차적으로 탐색하면서, target과 같은 값이 나올 때 까지 검색한다.
나온다면 현재 cursor가 가리키는 node의 포인터를, 없다면 NULL을 반환한다.
다음은 노드 클래스에서 인자로 들어온 노드 로부터 n번째 노드를 반환하는 함수를 구현해보자.
node *list_locate(node *head_ptr, size_t position) { node *cursor; assert(0 < position); cursor = head_ptr; for (size_t i = 1; (cursor != NULL && i < position); i++) { cursor = cursor->link(); } return cursor; } const node *list_locate(const node *head_ptr, size_t position) { const node *cursor; assert(0 < position); cursor = head_ptr; for (size_t i = 1; (cursor != NULL && i < position); i++) { cursor = cursor->link(); } return cursor; }마찬가지로 두 개를 만들어준 이유는, 선언한 node가 const 타입일 수도 아닐 수도 있기 때문이다.
(노드 클래스의 getter 함수와 같은 이유)
만약 찾고자 하는 인덱스(position, n)가 0보다 작다면 에러를 발생시킨다.
cursor가 head_ptr부터 head_ptr이 가리키는 노드를 계속해서 순차적으로 탐색하면서 i 값을 증가시킨다.
만약, i 값이 n번째(position)에 도달했다면, 반복문을 빠져나가고 현재 커서가 가리키고 있는 노드의 포인터를 반환한다.
만약 position이 1이라면, 반복문을 수행하지 않고 바로 head_ptr의 값이 저장된 cursor의 포인터가 반환된다.
다음은 노드 클래스에서 연결 리스트를 복사하는 함수를 구현해보자.
void list_copy(const node *source_ptr, node *&head_ptr, node *&tail_ptr) { head_ptr = tail_ptr = NULL; if (source_ptr == NULL) { return; } list_head_insert(head_ptr, source_ptr->data()); tail_ptr = head_ptr; while (source_ptr != NULL) { list_insert(tail_ptr, source_ptr->data()); tail_ptr = tail_ptr->link(); source_ptr = source_ptr->link(); } }list_head_insert와 마찬가지로 인자로 전달되는 연결 리스트의 처음과 끝을 가리키는 포인터의 값을 변화시켜야 하기 때문에,
reference 타입으로 인자를 받아준다.
그 후 head, tail_ptr을 NULL로 초기화 해주고,
만약, 복사 대상의 source_ptr이 비어있는 연결 리스트라면 바로 함수를 종료시켜준다.
아니라면, list_head_insert함수를 이용해서 head_ptr의 주소와 복사 대상의 data를 넘겨준다.
이 때, head_ptr의 값은 NULL이기 때문에, 새로 만들어지는 첫 번째 노드->link()는 NULL이 된다.
(물론 새로 만들어지는 첫 번째 노드->data()는 source_ptr->data()값이 그대로 들어간다)
다음은 source_ptr이 NULL값을 포인팅 할 때 까지 source_ptr->link()를 순차적으로 검색하면서 반복하게 되는데,
각 스탭에선 list_insert 함수를 이용해서 tail_ptr 뒤에 새로운 노드를 만들어 주게 된다.
그리고 tail_ptr의 값을 tail_ptr이 가리키는 노드의 포인터로 바꾸는데, 이렇게 되면 꼬리물기 식으로 계속 뒤에 노드를 붙일 수 있다.
source_ptr이 NULL을 포인팅 하는 시점, 반복문이 종료되며 연결 리스트의 복사가 완료된다.
head_ptr은 새로 만들어진 배열의 처음을, tail_ptr은 새로 만들어진 배열의 끝을 포인팅 하게 된다.
다음은 노드 클래스에서 맨 앞(인자로 들어온)의 노드를 삭제하는 함수를 구현해보자.
void list_head_remove(node *&head_ptr) { node *remove_ptr = head_ptr; head_ptr = remove_ptr->link(); delete remove_ptr; }삭제할 head_ptr을 remove_ptr에 잠깐 백업하고,
head_ptr이 포인팅 하는 노드를 remove_ptr이 가리키는 노드로 바꿔준다.
(remove_ptr 대신 head_ptr을 써도 무방하다)
그 다음 백업했던 remove_ptr을 delete로 해제해주면, 기존 head_ptr이 지워지고,
(head_ptr, remove_ptr 모두 같은 메모리 공간을 포인팅 하기 때문)
결과적으로 head_ptr이 가리키던 노드가 새로운 head_ptr이 된다.
remove_ptr을 안 쓴다면(head_ptr을 백업을 안 한다면), head_ptr = head_ptr->link() 하는 순간,
기존의 head_ptr이 가리키던 메모리 공간에 더이상 접근을 할 방법이 없어지기 때문에 반드시 백업을 해야한다.
다음은 노드 클래스에서 특정 노드의 다음 노드를 삭제하는 함수를 구현해보자.
void list_remove(node *previous_ptr) { node *remove_ptr; remove_ptr = previous_ptr->link(); previous_ptr->set_link(remove_ptr->link()); delete remove_ptr; }remove_ptr에 previous_ptr이 가리키고 있는 노드의 포인터를 넘겨준다.
즉, remove_ptr은 삭제해야 할 노드가 된다.
이 후, previous_ptr이 가리키는 노드를 remove_ptr이 가리키는 노드로 바꿔준다.
(remove_ptr 대신 previous_ptr을 써도 무방하다)
그리고나서 remove_ptr을 delete을 이용해 해제하면 구현 완료!
list_head_remove 함수와 다르게 previous_ptr를 넘겨줄 때 reference 타입이 아닌 그냥 value 타입으로 넘겨준 이유는
위에 list_insert와 동일한 이유이다.
마지막으로 노드 클래스의 연결 리스트를 완전히 비워주는 함수를 구현해보자.
void list_clear(node *&head_ptr) { while (head_ptr != NULL) { list_head_remove(head_ptr); } }연결 리스트의 특성상 뒤에서 앞으로 진행하며 제거하는 방식은 매우 어려울 뿐더러 시간도 오래 걸린다.
따라서 head_ptr의 위치를 뒤로 옮겨가며 지우는 방법이 바람직하다.
head_ptr이 NULL값을 가리킬 때 까지 list_head_remove함수를 호출하면 구현이 완료된다.
각 스텝마다 head_ptr이 가리키던 노드가 삭제되고 다음 노드로 head_ptr위치가 바뀌게 되는 원리를 이용한 것이다.
드디어 연결 리스트 자료 구조를 사용하기 위한 기초적인 기능 구현이 끝났다.
이젠, 구현한 노드 클래스를 이용해서 가방을 만들어보자.
연결 리스트로 구현된 가방은 기존 배열을 사용한 가방과 다른 세 가지 특징을 갖고 있다.
- 기본적으로 정해진 크기가 없다.
- 가방의 크기를 늘려줄 reserve 함수가 필요 없다.
- 가방의 크기를 늘리고 줄이는게 자유롭다.
- bag class
우선 가방 클래스의 생성자와 파괴자부터 구현해보자.
// Constructor bag::bag() { head_ptr = NULL ; many_nodes = 0 ; } // Copy constructor bag::bag(const bag &source) { node *tail_ptr; list_copy(source.head_ptr, head_ptr, tail_ptr); many_nodes = source.many_nodes; } // Destructor bag::~bag() { list_clear(head_ptr); }기본 생성자는 단순히 head_ptr가 NULL을 포인팅 하도록 해주고,
복사 생성자는 앞서 구현해놓은 list_copy 함수를 통해 구현해준다.
(tail_ptr은 필요 없는데, list_copy 함수 호출시 필요하기 때문에 선언해줬다)
마지막으로 파괴자는 단순히 앞서 구현한 list_clear 함수를 호출하면 구현 끝!
다음은 가방 클래스의 Assignment operator (=) overloading을 구현해보자.
bag &bag::operator=(const bag &source) { node *tail_ptr; if (this == &source) return *this; list_clear(head_ptr); many_nodes = 0; list_copy(source.head_ptr, head_ptr, tail_ptr); many_nodes = source.many_nodes; return *this; }만약 b1(this) = b1(source)같이 같은 가방 객체가 들어오는 경우 그냥 자신을 리턴한다.
그렇지 않다면, 현재 자신이 참조 하던 연결 리스트를 list_clear 함수를 통해 비워주고,
list_copy 함수를 통해 인자로 들어온 가방과 똑같은 연결 리스트를 만들어 할당 해준다.
*this, 즉, 가방 객체를 리턴하기 때문에 b1 = b2 = b3같은 연속된 연산도 수행이 가능하다.
리턴 타입이 bag가 아닌 bag & 인 이유는 Dynamic array때와 마찬가지로 전달의 효율성 때문이다.
다음은 가방 클래스의 Self-increment operator (+=) overloading을 구현해보자.
void bag::operator +=(const bag& addend) { node *copy_head_ptr, *copy_tail_ptr; if (addend.many_nodes > 0) { list_copy(addend.head_ptr, copy_head_ptr, copy_tail_ptr); copy_tail_ptr->set_link(head_ptr); head_ptr = copy_head_ptr; many_nodes += addend.many_nodes; } }이 연산자 오버로딩에서는 b1(왼쪽 피연산자) += b2(오른쪽 피연산자) 기능 수행시
연결 리스트가 b1 끝에 b2의 처음이 붙는 방식이 아닌, b2의 끝에 b1의 처음이 붙는 방식으로 구현할 것이다.
왜냐하면, b1의 tail_ptr을 갖고 있지 않기 때문이다. (list_locate(b1, b1->size());로 찾을 수도 있겠지만,
이 가방은 데이터의 순서가 중요하지 않으므로 쓸데없는 연산은 생략하여 성능을 챙기도록 했다)
만약 복사할 대상이 갖고 있는 데이터가 없다면, 기능을 수행하지 않는다.
아니라면, 복사할 대상(오른쪽 피연산자)의 addend 가방을 list_copy 함수를 이용해
copy_head_ptr, copy_tail_ptr에 복사해주자.
그 다음 복사한 copy_tail_ptr가 가리키는 링크를 왼쪽 피연산자의 head_ptr로 연결해주고,
왼쪽 피연산자의 기존 head_ptr을 복사한 copy_head_ptr로 바꿔준다.
이 연산 이후 b2 뒤에 b1이 붙은 연결 리스트가 b1에 저장된다.
다음은 가방 클래스에서 특정 데이터 하나를 제거하는 함수를 구현해보자.
bool bag::erase_one(const value_type& target) { node *target_ptr; target_ptr = list_search(head_ptr, target); if (target_ptr == NULL) return false; target_ptr->set_data(head_ptr->data()); list_head_remove(head_ptr); --many_nodes; return true; }연결 리스트의 특성상 다음에 어떤 노드가 연결되어 있는지는 알아도, 이전에 어떤 노드가 연결되어 있었는지는 모른다.
따라서 target인 값이 저장된 노드를 찾아도, 그 노드의 전에 연결된 노드를 알 수 없기에
target인 값이 저장된 노드의 전 노드와 다음 노드를 연결할 방법이 없다.
따라서 이 함수에서는 head_ptr에 저장된 값을 target인 값이 저장된 노드에 덮어 씌우고, head_ptr을 하나 지우는 방식으로 구현한다.
list_search 함수로 head_ptr(처음)부터 target인 값이 들어있는 노드가 나올 때 까지 검사를 하고,
노드가 나오면 그 포인터를 target_ptr에 저장한다.
target_ptr이 NULL이라면 list_search에서 target값이 저장된 노드를 찾지 못했다는 뜻이므로 false를 반환한다.
아니라면 target_ptr의 값을 head_ptr의 값으로 바꾸고,
list_head_remove 함수로 head_ptr를 하나 지운다.
다음은 가방 클래스에서 데이터를 하나 추가하는 함수를 구현해보자.
void bag::insert(const value_type &entry) { list_head_insert(head_ptr, entry); ++many_nodes; }앞서 여려차례 언급했 듯 연결 리스트의 마지막 노드를 찾는건 쉽지 않다.
tail_ptr을 저장하지 않았기 때문이다.
따라서 새로운 데이터를 넣을 때, 끝에 넣는게 아닌 맨 앞에 넣어주도록 구현하는게 편하다.
결국 이 기능은 list_head_insert 함수를 이용하면 간단하게 구현할 수 있다.
다음은 가방 클래스에서 특정 데이터가 몇개나 들어있는지 세주는 함수를 구현해보자.
bag::size_type bag::count(const value_type &target) const { size_type answer = 0; const node *cursor; cursor = list_search(head_ptr, target); while (cursor != NULL) { ++answer; cursor = cursor->link( ); cursor = list_search(cursor, target); } return answer; }우선 cursor 포인터의 값을 list_search를 이용해서 찾고자 하는 데이터가 들어있는 첫 번째 노드의 주소를 넣어주자.
그 다음, while문을 이용해 cursor가 NULL을 참조할 때 까지 반복하는데,
cursor을 cursor가 가리키는 노드, 즉 찾고자 하는 데이터가 들어있는 노드가 가리키는 노드로 바꿔준 후,
바뀐 cursor를 이용해 다시 list_search 함수를 실행시킨다.
list_search의 결과가 NULL이 아니라면 찾고자 하는 데이터가 또 있었다는 뜻이고,
때문에 answer값을 하나 증가시키고 이 과정을 반복한다.
NULL이라면 while문을 종료시키고 결과를 리턴한다.
마지막으로 장난삼아 가방 클래스에서 아무 데이터 하나를 리턴하는 함수를 구현해보자.
bag::value_type bag::grab() { size_type i; const node *cursor; assert(size() > 0); i = (rand() % size()) + 1; cursor = list_locate(head_ptr, i); return cursor->data( ); }가방에 저장된 데이터가 없다면 에러를 발생시킨다.
아니라면, rand 함수를 이용해서 랜덤한 위치의 인덱스 값을 얻는다.
구현한 연결 리스트 자료 구조에서는 인덱스가 1번 부터 시작하기 때문에(list_locate 함수 참조) i 에 1을 더해준 것이다.
그 다음 list_locate 함수를 이용해 i 번째 인덱스에 해당하는 노드의 포인터를 가져온 후
cursor->data()로 반환되는 값을 리턴한다.
데이터의 저장과 삭제, 메모리 효율성 측면에서는 배열보다 연결 리스트가 더 효율적이다.
하지만, 데이터에 random access 성능 차원에선 배열이 연결 리스트를 압도한다.
이런 링크 리스트의 단점을 완벽하게 커버할 수는 없지만, 어느정도 해소는 가능한 자료 구조가 하나 있다.
바로 이중 연결 리스트이다.
class dnode { public: typedef double value_type; ... private: value_type data_field; dnode *link_fore; dnode *link_back; };이 자료 구조의 경우 하나의 노드에 두 개의 노드 포인터 멤버 변수가 있는데, 앞-뒤로 연결되어 있다.
따라서 데이터를 제거하는 경우, 특정한 위치에서 바로 지울 수도 있고,
연결 리스트의 끝에서 부터 앞으로 탐색하는 것도 가능해진다.
구현은 위에 구현한 방법에서 약간만 더 고민하면 간단하게 할 수 있을 것이다.
참고로 c++ STL에서 제공하는 vector 클래스는 이중 연결 리스트로 구현되어 있다고 한다...
'대학 > 자료구조' 카테고리의 다른 글
Stack (2) 2022.12.04 c++ template, iterator (0) 2022.10.18 Dynamic array (0) 2022.10.17 Static array (0) 2022.10.16 c++ operator overloading (0) 2022.10.16