-
java collection framework대학/객체지향프로그래밍 2022. 12. 10. 21:48
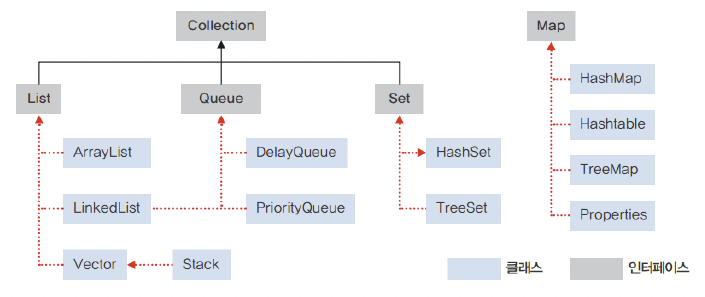
데이터를 한 곳에 모아 저장 및 관리하는 가변 크기의 객체 컨테이너를 컬렉션이라 부른다.
- Collection
컬렉션 인터페이스에는 여러 추상 메서드가 있지만, 구현된 메서드는 다음과 같다.
default void forEach(Consumer<? super T> action)모든 원소에 대해 action을 수행한다. action의 인자로 람다표현식을 전달하면 된다.
default boolean removeIf(Predicate<? super E> filter)filter의 결과가 true면 원소를 삭제한다. 역시 람다표현식을 전달하면 된다.
이제 Collection 하위의 인터페이스와 클래스를 살펴보자.
1. List 인터페이스
import java.util.Arrays; import java.util.List; public class App { public static void main(String[] args) { String[] animals1 = { "Deer", "Tiger", "Seal", "Bear" }; List<String> animals2 = Arrays.asList(animals1); animals2.set(1, "Parrot"); // animals2.add(0, "Wolf"); for (String s : animals2) System.out.print(s + ", "); System.out.println(); String[] animals3 = animals2.toArray(new String[0]); for (int i = 0; i < animals3.length; i++) System.out.print(animals3[i] + ", "); System.out.println(); List<String> car = List.of("Grandeur", "Sonata", "Avante", "Genesis"); car.forEach(s -> System.out.print(s + " ")); // car.set(1, "Santa Fe"); // List<Object> objects = List.of("a", null); } }asList, toArray 메서드로 배열과 리스트 간 상호 변환할 수 있다.
of 메서드는 인자로 들어온 원소들을 불변 리스트로 변환한다. 즉 생성된 리스트 객체의 데이터를 변경할 수 없다.
adList로 생성된 리스트 객체의 데이터는 set메서드로 변경은 할 수 있지만, 크기는 고정되기 때문에 add메서드를 사용할 수 없다.
참고로, null을 원소로 가질 수 없으며, 인자 1개~10개를 갖는 메서드를 오버로딩하여 구현했기에 11개 이상의 인자를 받을 수는 없다.
import java.util.*; public class App { public static void main(String[] args) { Collection<String> list = Arrays.asList("A", "B", "C"); Iterator<String> iterator = list.iterator(); while (iterator.hasNext()) System.out.print(iterator.next() + ","); System.out.println(); while (iterator.hasNext()) System.out.print(iterator.next() + ","); System.out.println(); iterator = list.iterator(); while (iterator.hasNext()) System.out.print(iterator.next() + ","); System.out.println(); } } // A,B,C, // // A,B,C,iterator 인터페이스도 지원한다.
a. ArrayList 클래스
Vector 클래스와 유사하지만 ArrayList는 동기화된 메서드로 구현되었다. 즉, 멀티 스레드 환경에서 안전하다.
import java.util.ArrayList; import java.util.List; public class App { public static void main(String[] args) { List<String> list = List.of("Grandeur", "Sonata", "Avante", "Genesis", "Soul"); System.out.println(list.indexOf("Sonata")); // 1 System.out.println(list.contains("Santa Fe")); // false List<String> cars1 = new ArrayList<>(list); cars1.add("Santa Fe"); cars1.removeIf(c -> c.startsWith("So")); cars1.replaceAll(s -> "New " + s); cars1.forEach(s -> System.out.print(s + " ")); // New Grandeur New Avante New Genesis New Santa Fe System.out.println(); cars1.clear(); // remove all elements System.out.println(cars1.isEmpty()); // true } }b. Stack 클래스
Vector의 자식 클래스로 인덱스가 1부터 시작하는 것이 특징이다.
import java.util.Stack; public class App { public static void main(String[] args) { Stack<String> s1 = new Stack<>(); s1.push("Apple"); s1.push("Banana"); s1.push("Cherry"); System.out.println(s1.peek()); // Cherry System.out.println(s1.pop()); // Cherry System.out.println(s1.pop()); // Banana System.out.println(s1.pop()); // Apple System.out.println(); Stack<Integer> s2 = new Stack<>(); s2.add(10); s2.add(20); s2.add(1, 100); System.out.println(s2.search(10)); // 3 for (int value : s2) System.out.print(value + " "); // 10 100 20 System.out.println(); while (!s2.empty()) System.out.print(s2.pop() + " "); // 20 100 10 } }LIFO 구조로 설계되었기 때문에 가장 먼저 나올 원소가 인덱스 1번이 된다.
c. LinkedList 클래스
ArrayList는 원소를 중간에 추가/삭제시 인덱스의 조정이 필요했다면,
LinkedList는 전후 원소의 참조값만 조정하면 된다.
즉, 각각의 장단점이 존재한다.
import java.util.ArrayList; import java.util.LinkedList; public class App { public static void main(String[] args) { ArrayList<Integer> al = new ArrayList<Integer>(); LinkedList<Integer> ll = new LinkedList<Integer>(); long start = System.nanoTime(); for (int i = 0; i < 100000; i++) al.add(0, i); long end = System.nanoTime(); long duration = end - start; System.out.println("ArrayList processing time: " + duration); start = System.nanoTime(); for (int i = 0; i < 100000; i++) ll.add(0, i); end = System.nanoTime(); duration = end - start; System.out.println("LinkedList processing time: " + duration); } } // ArrayList processing time: 474120458 // LinkedList processing time: 3458458특히 add, remove 연산에서 LinkedList의 진가가 발휘된다.
참고로 LinkedList는 역방향의 iterator까지 지원한다.
2. Queue 인터페이스
import java.util.LinkedList; import java.util.NoSuchElementException; import java.util.Queue; public class App { public static void main(String[] args) { Queue<String> q = new LinkedList<>(); // q.remove(); System.out.println(q.poll()); // null q.offer("Apple"); System.out.println("Did you add Banana? " + q.offer("Banana")); // Did you add Banana? true try { q.add("Cherry"); } catch (IllegalStateException e) { } System.out.println("Head: " + q.peek()); // Head: Apple String head = null; try { head = q.remove(); System.out.println(head + " removed"); // Apple removed System.out.println("New head: " + q.element()); // New head: Banana } catch (NoSuchElementException e) { } head = q.poll(); System.out.println(head + " removed"); // Banana removed System.out.println("New head: " + q.peek()); // New head: Cherry } }기본적으로 앞에 추상 메서드가 구현된 add, remove, element 메서드를 사용할 수 있지만,
이 메서드들은 사용함에 있어 예외를 던질 수 있기에 예외처리문을 구현해야 하는 번거로움이 존재한다.
하지만 offer, poll, peek 과 같은 메서드는 예외를 던지는 대신 null, false와 같은 값을 반환하기에 사용이 편리하다.
3. Set 인터페이스
순서가 없으며, 중복되지 않는 객체를 저장하는 자료구조이다.
그 중에 HashSet 클래스를 살펴보자.
import java.util.Arrays; import java.util.HashSet; import java.util.List; import java.util.Set; public class App { public static void main(String[] args) { String[] fruits = { "Apple", "Banana", "Grape", "Watermelon" }; Set<String> h1 = new HashSet<>(); Set<String> h2 = new HashSet<>(); for (String s : fruits) h1.add(s); System.out.println(h1); // [Apple, Watermelon, Grape, Banana] h1.add("Banana"); h1.remove("Grape"); h1.add(null); System.out.println(h1); // [null, Apple, Watermelon, Banana] System.out.println(h1.contains("Watermelon")); // true List<String> list = Arrays.asList(fruits); h2.addAll(list); System.out.println(h2); // [Apple, Watermelon, Grape, Banana] } }HashSet은 해싱을 이용하여 Set을 구현했기에 탐색 속도가 매우 빠르다.
여담으로 해시해서 생각났는데,,,
같은 객체의 기준은 hashCode()의 반환 값이 같아야 하고,
이어서 equals()의 반환 값이 true인 두 객체를 말한다.
- Map
맵 인터페이스는 키-값의 쌍으로 구성된 객체를 저장하는 자료구조이다.
키와 값은 모두 객체이고, 키는 중복되지 않으며 하나의 값에만 매핑되어있다.
import java.util.HashMap; import java.util.Map; public class App { public static void main(String[] args) { Map<String, Integer> map = Map.of("Apple", 5, "Banana", 3, "Grape", 10, "Strawberry", 1); Map<String, Integer> fruits = new HashMap<>(map); System.out.println("# of fruit: " + fruits.size()); // # of fruit: 4 fruits.remove("Banana"); System.out.println("# of fruit: " + fruits.size()); // # of fruit: 3 fruits.put("Mango", 2); System.out.println("After adding Mango: " + fruits); // After adding Mango: {Mango=2, Apple=5, Grape=10, Strawberry=1} fruits.clear(); System.out.println("# of fruit: " + fruits.size()); // # of fruit: 0 } }- Collections 클래스
컬렉션을 다루는 다양한 메서드를 제공한다.
import java.util.Arrays; import java.util.Collections; import java.util.List; public class App { public static void main(String[] args) { String[] fruits = { "Grape", "Watermelon", "Apple", "Kiwi", "Mango" }; List<String> list = Arrays.asList(fruits); Collections.sort(list, Collections.reverseOrder()); System.out.println(list); // [Watermelon, Mango, Kiwi, Grape, Apple] Collections.reverse(list); System.out.println(list); // [Apple, Grape, Kiwi, Mango, Watermelon] } }'대학 > 객체지향프로그래밍' 카테고리의 다른 글
java 네트워크 프로그래밍 (0) 2022.12.10 java lambda expression / 메서드 참조 (0) 2022.12.10 java generic(2) (0) 2022.12.10 java generic(1) (0) 2022.12.09 java transient / volatile / instanceof / native / assert (0) 2022.12.09