-
모든 예시는 sqlite3을 기준으로 작성하였습니다.
이 포스트에서는 아래의 내용을 다룹니다.
- Join
- inner
- left outer
- right outer
- full outer
- natural
- on
- using
- Views
- update view
- Simple View
- Transactions
- Integrity Constraints
- not null
- primary key
- unique
- check
- references
- on (Action)
- Built-in Data Type
- date
- time
- timestamp
- interval
- julianday
- Large-Object Type
- blob
- clob
- Index
- Output Redirection
Join
join 연산은 Cartesian-Product와 Select 연산의 합으로 구현할 수 있다.
Join Types
Join types description (inner) join 두 테이블의 condition에 따라 합칠 때 교집합이 되도록 left (outer) join 두 테이블의 condition에 따라 합칠 때 왼쪽 테이블이 기준이 되도록 right (outer) join 두 테이블의 condition에 따라 합칠 때 오른쪽 테이블이 기준이 되도록 full (outer) join 두 테이블의 condition에 따라 합칠 때 합집합이 되도록 Join Conditions
Join conditions description natural 공통 attribute의 데이터가 같은 것만 선택 on <predicate> predicate 조건문이 true인 데이터만 선택 using (A1, ..., An) A1, ..., An attribute의 데이터가 같은 것만 선택 - inner join
select name, course_id from student, takes where student.ID = takes.ID; -- select name, course_id from student natural (inner) join takes;join 하고자 하는 테이블간 공통된 attribute의 값이 같은 데이터만 join하여 출력한다.
그 때문에 주의해야 할 점이 있다.
-- correct select name, title from student natural join takes, course where takes.course_id = course.course_id; -- incorrect select name, title from student natural join takes natural join course;공통된 attribute의 값이 모두 같을 때에만 데이터를 출력하기 때문에,
의도했던 student.ID = takes.ID 뿐만 아니라 student.dept_name = course.dept_name 까지 검사를 하게 되기 때문에
의도했던 것과 다르게 데이터의 누락이 생길 수 있다.
하지만 natural inner join의 경우 공통된 attribute에 해당하는 데이터가 양쪽 테이블에 존재하지 않을 경우
정보의 손실이 발생할 수 있다.
정보의 손실을 방지하고 대신 null 값으로 빈 값을 채우는 방법은 outer join을 사용하면 된다.
- outer join
-- A, B를 join 하는데 A 테이블에서 데이터 손실이 없도록, -- B 테이블에 존재하지 않는기에 표시할 수 없는 데이터는 null로 from A natural left (outer) join B -- A, B를 join 하는데 B 테이블에서 데이터 손실이 없도록, -- A 테이블에 존재하지 않는기에 표시할 수 없는 데이터는 null로 from A natural right (outer) join B -- A, B를 join 하는데 양쪽 테이블에서 데이터 손실이 없도록, -- 다른 테이블에 존재하지 않는기에 표시할 수 없는 데이터는 null로 from A natural full (outer) join B* in relational algebra
natural left outer join

natural right outer join

natural full outer join
테이블 예시를 들어 모든 경우의 수를 살펴보며 이해해보자.
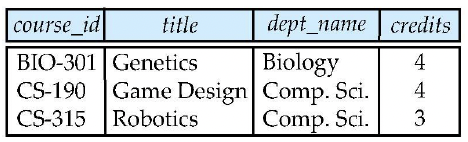
<Fig. 01> course relation 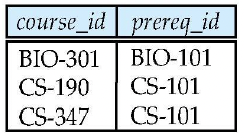
<Fig. 02> prereq relation select * from course natural __ inner/outer join prereq;natural (inner) join
course_id title dept_name credits prereq_id BIO-301 Genetics Biology 4 BIO-101 CS-190 Game Design Comp. Sci. 4 CS-101 course_id 가 공통으로 존재하고, 이 attribute의 데이터가 같은, BIO-301, CS-190의 과목만 join되어 출력되었다.
course relation에서는 CS-315, prereq relation에서는 CS-347의 데이터가 손실되었다.
natural left (outer) join
course_id title dept_name credits prereq_id BIO-301 Genetics Biology 4 BIO-101 CS-190 Game Design Comp. Sci. 4 CS-101 CS-315 Robotics Comp. Sci. 3 null course_id 가 공통으로 존재하고, 이 attribute의 데이터가 같은 데이터끼리 join되어 출력되었다.
course relation에서 데이터 손실은 발생하지 않았으나,
prereq relation에서 CS-315에 대한 데이터가 없었기에 null로 표기되었다.
natural right (outer) join
course_id title dept_name credits prereq_id BIO-301 Genetics Biology 4 BIO-101 CS-190 Game Design Comp. Sci. 4 CS-101 CS-347 null null null CS-101 course_id 가 공통으로 존재하고, 이 attribute의 데이터가 같은 데이터끼리 join되어 출력되었다.
prereq relation에서 데이터 손실은 발생하지 않았으나,
course relation에서 CS-347에 대한 데이터가 없었기에 null로 표기되었다.
natural full (outer) join
course_id title dept_name credits prereq_id BIO-301 Genetics Biology 4 BIO-101 CS-190 Game Design Comp. Sci. 4 CS-101 CS-315 Robotics Comp. Sci. 3 null CS-347 null null null CS-101 course_id 가 공통으로 존재하고, 이 attribute의 데이터가 같은 데이터끼리 join되어 출력되었다.
양쪽 relation에서 데이터 손실은 발생하지 않았으나,
course relation에서 CS-347에 대한 데이터가 없었기에 null로 표기되었다.
- natural
위에서 지금껏 봐왔듯 자연스러운 join을 위함
즉, 양쪽 테이블에 공통 attribute의 데이터가 같은 tuple만 출력
- using
select name, title from student natural join takes, course where takes.course_id = course.course_id; -- select name, title from student natural inner join takes inner join course using (course_id);natural 은 모든 공통 attribute를 비교한다. 따라서 위의 inner join에서 있었던,
논리적 연관성이 없는 attribute까지 비교해 데이터 손실이 발생할 수 있었다.
using은 특정 attribute만 비교하여 그 문제를 해결할 수 있게 해준다.
- on
select * from course inner join prereq on course.course_id = prereq.course_id;course_id title dept_name credits prereq_id course_id BIO-301 Genetics Biology 4 BIO-101 BIO-301 CS-190 Game Design Comp. Sci. 4 CS-101 CS-190 on 절의 조건에 충족하는 테이블을 join연산 할 수 있도록 해준다.
또한 natural, using과 다르게 중복되는 attribute의 제거 없이 모든 attribute를 출력한다.
(이 경우 course_id가 중복 출력)
Views
사용자에 따라 다르게 데이터를 표시해줘야 하는 경우가 있다.
예로들어 instructor 테이블에서 연봉 정보를 제외하고 보여줘야 하는 경우가 있을 수 있다.
create view instructor_view as select ID, name, dept_name from instructor;이럴 때 salary attribute를 제외한 가상의 테이블, view를 만들어 보여주면 된다.
create view dept_total_salary (dept_name, total_salary) as select dept_name, sum (salary) from instructor group by dept_name;위와 같이 attribute의 이름을 바꿀 수도 있고, 조건을 집어넣어 특정 tuple만 가져올 수도 있다.
사용은 with절로 만든 테이블과 같은 방식으로 사용할 수 있다. (view를 이용해 view를 만들수도 있다는 뜻!)
차이점은 with은 쿼리문 내부에서만 사용할 수 있지만, view는 계속 남는다는 점이다.
주의할 점은 view는 가상의 테이블이기 때문에 실체가 없다.
즉, view를 사용하면 그 view 대신 view를 정의할 때 사용한 쿼리문이 들어가게 된다. (마치 변수처럼)
결국 view를 사용해서 쿼리문을 작성해도
실제로 처리되는 쿼리문은 재귀적으로 view가 날것의 쿼리문으로 풀어져 실행되게 된다.
따라서, view에 많이 의존하면 처리속도가 느려질 수 있다.
어떤 DBMS는 view를 실체화해서 저장하기도 하는데,
그런 경우 속도는 빨라도 의존성있는 테이블에 변화가 생길 경우
view 또한 지속적으로 업데이트 해줘야 한다는 단점이 있다.
- Update View
일반적으로 view를 업데이트 하는 행위는 불가능하거나 제한적으로밖에 안된다.
view는 기존 여러 테이블로 부터 제한된 데이터를 가져와 생성하는데,
그런 view를 수정하려고 하면 논리적인 에러가 있는 데이터를 추가 할 수도 있고,
view에는 존재하지 않는 attribute의 값을 null로 처리할 수 밖에 없는 상황이 생기기 때문이다.
이런 상황을 방지하기 위해 제한적인 상황에서만 허용하는데, 그 상황은
simple view를 업데이트 하는 상황이다.
* Simple View
1. from 절에는 오직 하나의 relation만 사용할 것.
2. select 절에는 오직 attribute의 이름만 사용할 것.
(사칙연산식, aggregate function 사용금지, distinct 키워드 사용금지)
3. relation에는 있지만, select 절에 등장하지 않는 attribute는 null 값을 사용할 수 있어야 한다.
4. aggregate function이 쓰이지 않은 만큼, group, having 절은 사용할 수 없다.Transactions
은행 계좌 이체를 예로 들어보자.
A -> B 로 송금하는 경우 DB에서는 아래와 같은 스탭을 밟게 된다고 가정해보자.
1. A 에서 a만큼의 금액을 출금
2. B 에서 a만큼의 금액을 입금근데 만약, 1번 스탭을 진행한 직후 DB가 정지하는 일이 발생했다고 해보자.
그럼 A에서 출금은 일어났는데 B에서 입금은 일어나지 않은 상황이 발생하게 된다.
이런 사태를 막기위해 DB는 transcation 기능을 제공한다.
transaction은 일종의 쿼리문 처리 단위로 transaction 시작-끝 사이에 있는 모든 문장을
하나의 작업인 것 처럼 처리한다.
즉, transaction 시작 부터 끝나기 전까지 어떤 에러가 발생하면 그 사이에 있는 모든 동작을 수행 취소하고
DB를 원상태로 복구시킨다(Rollback work).
에러가 발생하지 않으면 그 사이에 수행된 동작을 수행 완료 처리하여 DB에 업데이트 한다(Commit work).
참고로 transaction의 처음과 끝을 지정하지 않으면 sql은 기본적으로 하나의 쿼리문을 transaction 단위로 묶어 처리한다.
Integrity Constraints
테이블 생성시 아래와 같은 무결성 제약조건을 걸 수 있다.
- not null
name varchar(20) not nullnot null로 설정된 attribute는 null값을 허용하지 않게된다.
- primary key
primary key (course_id, sec_id, semester, year)candidate key 중 지정한 key를 primary key로 지정한다.
- unique
unique (A1, A2, ..., An)A1, A2, ..., An의 attribure의 순서쌍은 유일해야 한다는 제약조건이다.
즉, 일부 (A1, A2)의 값은 같을 수 있어도 (A1, A2, ..., An)의 값은 반드시 유일해야 한다.
참고로 unique로 지정된 attribute의 순서쌍은 정의에 따라 super key가 된다.
따라서 null값이 들어가도 되며, 그렇기에 foreign key가 null이 될 수 있는 것이다.
(단, primary key는 null이 되면 안됨)
- check
check (semester in ('Fall', 'Winter', 'Spring', 'Summer'))check 안의 조건이 충족된 데이터만 입력 받을 수 있다.
그렇기에 특정 attribute에 입력 가능한 데이터를 지정할 수 있다.
- references
foreign key (dept_name) references department -- foreign key (dept_name) references department (dept_name)테이블간 데이터를 참조할 경우에 제약조건을 걸 수 있다.
위 경우는 생성할 테이블의 foreign key로 dept_name attribute를 사용하는데,
그 값은 반드시 department 테이블의 primary key (또는 dept_name)에 존재하는 값이어야 한다.
- on (Action)
foreign key (dept_name) references department on delete cascade on update cascade참조한 테이블의 데이터가 변경되었을 경우 참조한 테이블의 데이터도 변경을 가할 수 있게된다.
위 경우는 department 테이블의 데이터가 delete, update되는 경우에
생성할 테이블의 dept_name도 같이 delete, update 한다는 뜻이다.
(delete의 경우 한 tuple이 전체 삭제)
만약 on delete set null (또는 default)로 지정했을 경우
department 테이블의 데이터가 삭제되는 경우 dept_name의 값을 null (또는 기본값) 으로 설정하게 된다.
Built-in Data Type
- date
date '2005-7-27'
- time
time '09:00:30'
time '09:00:30.75'- timestamp
date + time
timestamp '2005-7-27 09:00:30.75'
- interval
interval '1'day
interval은 date / time / timestamp를 substract한 값으로 얻을 수 있고,
date / time / timestamp 에 interval을 더하여 새로운 시각 데이터를 얻을 수 있다.
*julianday()
BC4713.1.1 일을 기준으로 며칠이 지났는지 계산해주는 함수로
단순한 timestamp의 사칙연산이 잘 안될경우(DBMS 마다 상이) 이 함수로 변환하여 계산하면 편하다.
Large-Object Type
blob: binary large object (photo, video, ... )
clob: character large object (large string)
위와 같은 큰 객체의 경우에는 데이터 자체를 넘겨주는 것이 아닌, 포인터 (링크, 엔드포인트)를 넘겨주게 된다.
Index
create index studentID_index on student (ID);특정 데이터를 빠르게 찾아오기 위해서 사용한다.
index를 정의하지 않으면, 특정 데이터를 찾기 위해서 테이블 전체를 훑어보는 작업이 필요하지만,
index를 정의하면 index는 내부적으로 hash-table을 이용해 정의되어 있기 때문에
빠르게 데이터에 접근이 가능해진다.
하지만, view와 마찬가지로 테이블이 업데이트 된 경우 index 역시 업데이트를 해줘야 한다.
Output Redirection
select distinct ID into StudentIds from student; -- create table StudentIds as select distinct ID from student;into 키워드를 쓰면 쿼리문의 결과를 출력하는 것이 아닌,
뒤에 붙은 테이블로 새로 저장할 수 있다.
단, 미리 정의된 테이블이 있어서는 안되고 (위 경우에는 StudentIds 라는 테이블이 이미 있었으면 안된다),
새로 정의되는 테이블의 column 수는 가져오는 attribute 수와 동일해진다.
'대학 > 데이터베이스' 카테고리의 다른 글
Database Storage (2) 2023.06.03 Normalization (0) 2023.06.03 Database Design using E-R model (0) 2023.04.15 SQL 입문 (1) 2023.04.12 데이터베이스 개념 (0) 2023.04.06 - Join